一步一步”手搓“一个简单的PE解析器
一步一步”手搓“一个简单的PE解析器
- 本文主要通过编写一个简单的PE解析器来加强对于PE结构的理解
- 项目地址:bladchan/Simple-PE-Parser: A simple tool for parsing PE file (github.com)
Step 0: 预备工作
- 了解PE文件结构,参考资料[1-7]均介绍了PE的结构,这里不再赘述
winnt.h,该头文件包含了很多PE文件格式中的结构体:https://github.com/Alexpux/mingw-w64/blob/master/mingw-w64-tools/widl/include/winnt.h- 开源项目:https://github.com/hasherezade/pe-bear
Step 1: 简单的识别PE文件与其类型
本节主要解决一个事,那就是确定给定的文件是否是一个PE文件
一个PE文件至少要满足两个条件:
DOS Header的标志MZ- 识别:文件前两个字节对应
MZ的ASCII(0x5A4D) 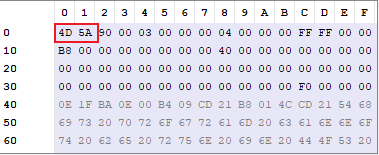
- 识别:文件前两个字节对应
NT Header的标志PE- 识别:1. 获取DOS Header的指向
NT Headers首部的偏移值;2. 取出前四个字节,并判断是否为50 45 00 00; 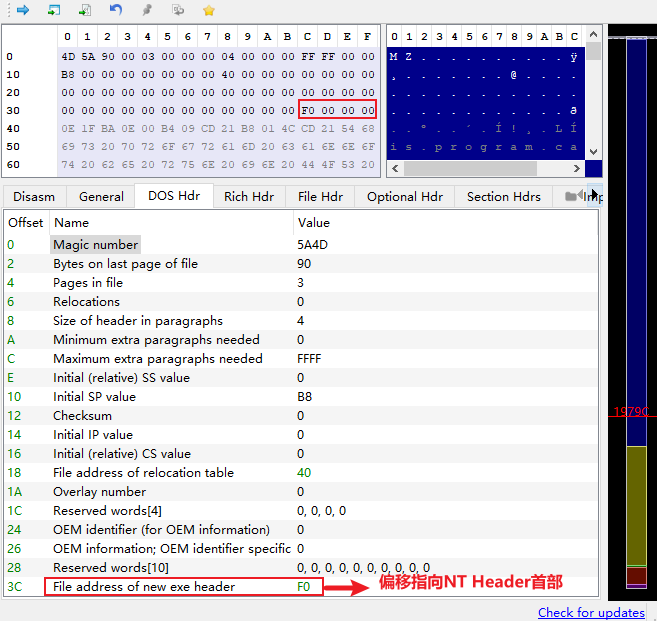

- 识别:1. 获取DOS Header的指向
接下来判断一下PE文件的类型,主要是通过
NT Headers的Optional Header进行识别:Optional Header:- 主要看Magic字段(两个字节):
0x10b ==> NT32,0x20b ==> NT64 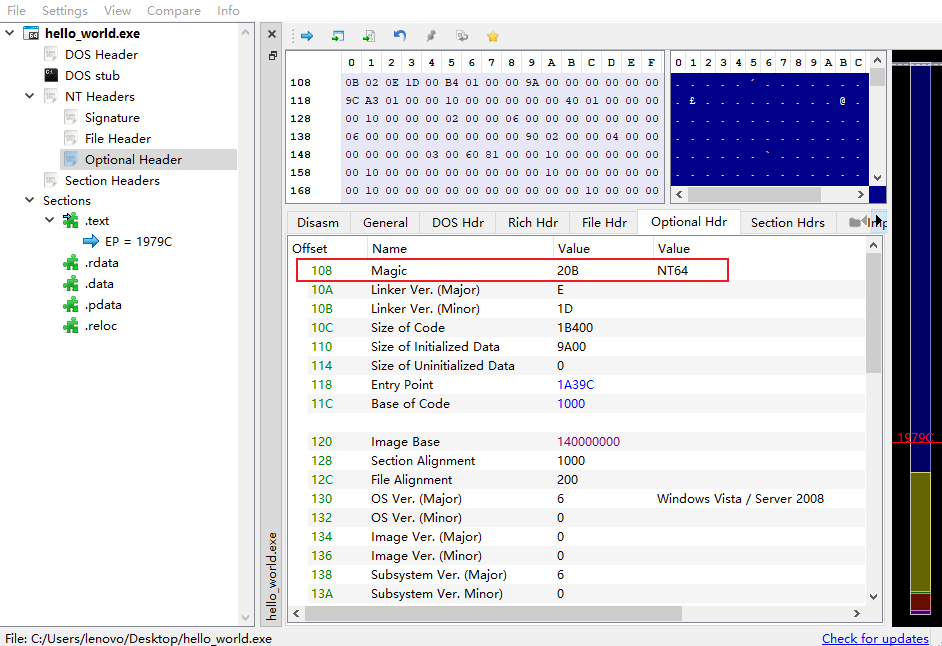
- 主要看Magic字段(两个字节):
- 代码:
1 | |
- 测试:
1 | |
输出结果为64,表示该PE文件类型为PE32+
Step 2: 解析PE32文件头
PE32和PE32+仅在位长上存在差异,整体处理逻辑是无任何区别的;PE32文件主要包括的结构有:DOS headerDOS Stub (Rich Header)NT Headers (File Header、Optional Header)Section Headers- …(请注意,我们这里仅仅是设计一个简单的解析器,解析的功能可能并不完善,仅用于加深对PE文件格式的理解)
PE32文件结构类的设计:
1 | |
Step 2.1: 解析DOS Header
- 在类中维护一个
IMAGE_DOS_HEADER的变量pe_dos_header,然后从文件中将相应数据读入到该成员变量即可。同时我们这里在类中维护了一个nt_headers_offset的成员变量,用于记录NT Headers的偏移值。 - 代码:
1 | |
- 运行结果:
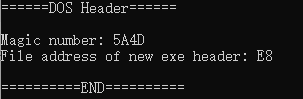
Step 2.2: 解析DOS Stub(Rich headers)
这一部分主要解析
DOS Stub中的Rich headers。请注意,暂无文档说明过Rich headers是包含在DOS Stub内的,但Rich headers所处的位置确实介于PE头和DOS头之间的,因此本文不严谨的将Rich headers包含在DOS Stub内部什么是
Rich headers?Rich headers可以理解为存储着开发环境信息的一段指纹[10],或用于帮助诊断和调试Rich headers使用XOR Key对Rich headers中的每4个字节进行了异或加密Rich headers的结构如下图所示:
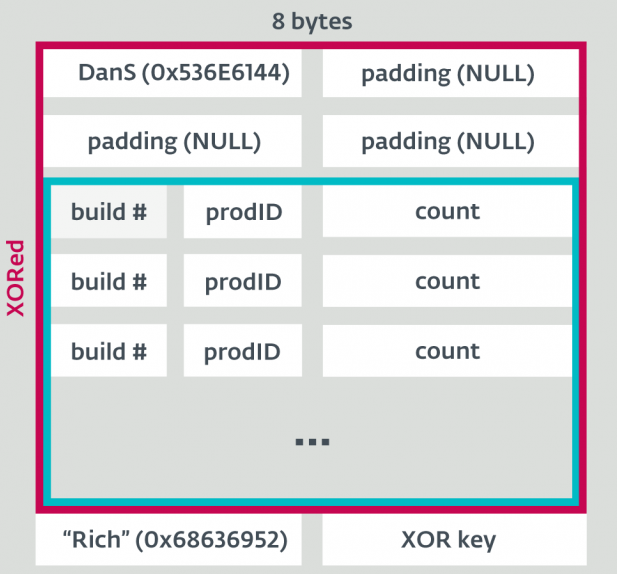
如何定位
Rich headers?- 首先,
Rich headers肯定是以四个字节的Rich(0x68636952),并且后面还跟着四个字节的XOR key; - 然后,为了确定
Rich headers的长度,我们向前搜索,并根据XOR密钥异或恢复原数据,并找到DanS ID(0x536e6144),这样一来我们就找到了Rich headers的起始位置; - 最后,我们使用
XOR密钥解密Rich headers的内容并恢复原数据。
- 首先,
设计结构体用来存储
Rich headers数据:
1 | |
- 处理逻辑代码:
1 | |
- 运行结果:

Step 2.3: 解析NT Headers
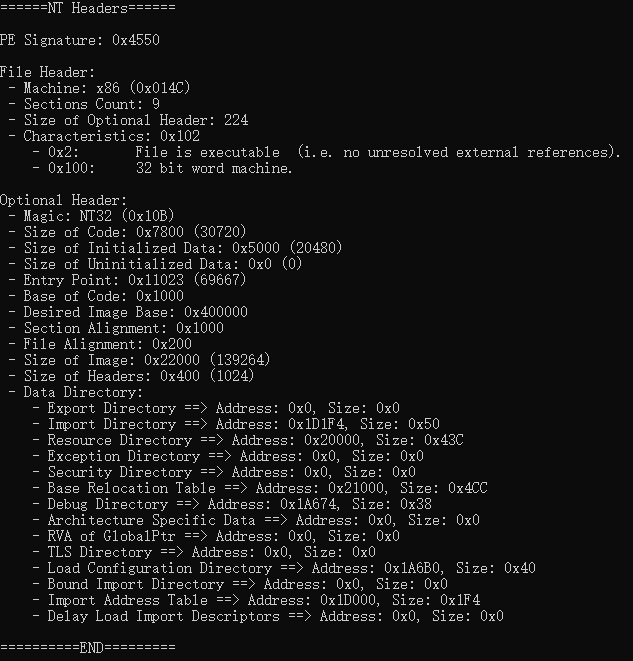
NT Headers包含三个部分,分别是PE Signature、File Header和Optional HeaderPE Signature:没有啥玩意,就是四个字节0x4550(PE..),用来表示PE头File Header:记录文件的一些信息,如计算机体系结构类型、节区数量、时间戳、Optional Header大小、PE文件属性等等Optional Header:可选头,包含一些程序执行的重要信息,如程序执行入口地址、程序首选装载地址、内存中节区对齐大小、文件中节区对齐大小、镜像大小、PE头大小等等
解析流程:
- 按照相关结构体的信息依次解析即可
处理逻辑代码:
1 | |
- 运行结果:
Step 2.4: 解析Section Headers
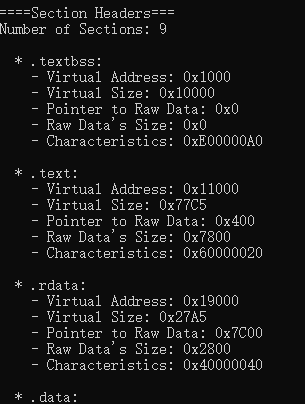
Section Headers:存储着与节区相关的信息,包括节区名、VirtualAddress、VirtualSize、PointerToRawData、SizeOfRawData、Characteristics等VirtualAddress:该节区载入内存中的偏移地址[11];VirtualSize:该节区在内存中的大小(内存对齐之前的长度:真实长度)[11];PointerToRawData:该节区在文件中的偏移地址[11];SizeOfRawData:该节区在文件中的大小(文件对齐之前的长度:真实长度)[11];Characteristics:用来表征该节区的一些属性,具体值详见PE Format - Win32 apps | Microsoft Learn
解析流程:
Section Headers在NT Headers之后,而NT Headers的值是固定的,可以通过nt_headers_offset偏移地址加上NT Headers的长度找到Section Headers在文件中的偏移地址;Section Headers中section数量由NT Headers - FileHeader中的NumberOfSections字段决定,因此可以通过该字段确定Section的数量;- 按照
___IMAGE_SECTION_HEADER结构体依次解析NumberOfSections个Section即可
处理逻辑代码:
1 | |
- 运行结果:
本节小结
- 本节主要解析了PE32文件的头部信息,包括
DOS Header、Rish Headers、NT Headers和Section Headers,并通过这种解析的过程了解了PE文件的结构,如下图所示:
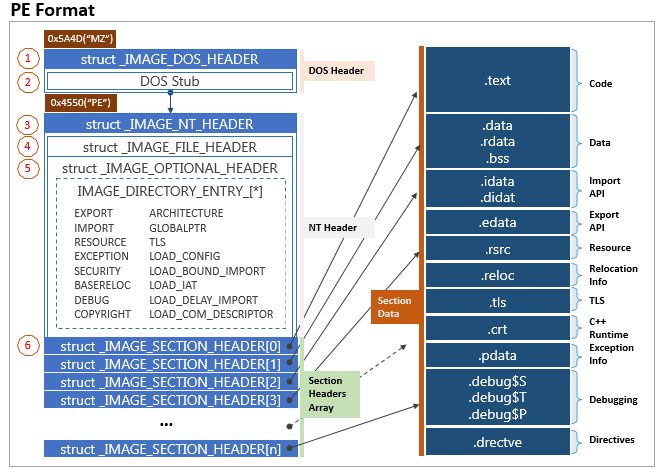
- 此外还剩下需要具体分析的是Section信息,我们将在下一节中详细介绍
Step 3: 解析Sections
- PE文件的Sections包括[12]:
| Section Name | Content | Characteristics |
|---|---|---|
| .bss | 未初始化数据(free format) | IMAGE_SCN_CNT_UNINITIALIZED_DATA | IMAGE_SCN_MEM_READ | IMAGE_SCN_MEM_WRITE |
| .cormeta | CLR metadata that indicates that the object file contains managed code | IMAGE_SCN_LNK_INFO |
| .data | 已初始化数据(free format) | IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ | IMAGE_SCN_MEM_WRITE |
| .debug$F | Generated FPO debug information (object only, x86 architecture only, and now obsolete) | IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ | IMAGE_SCN_MEM_DISCARDABLE |
| .debug$P | Precompiled debug types (object only) | IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ | IMAGE_SCN_MEM_DISCARDABLE |
| .debug$S | Debug symbols (object only) | IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ | IMAGE_SCN_MEM_DISCARDABLE |
| .debug$T | Debug types (object only) | IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ | IMAGE_SCN_MEM_DISCARDABLE |
| .drective | Linker options | IMAGE_SCN_LNK_INFO |
| .edata | 导出表 | IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ |
| .idata | 导入表 | IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ | IMAGE_SCN_MEM_WRITE |
| .idlsym | Includes registered SEH (image only) to support IDL attributes. For information, see “IDL Attributes” in References at the end of this topic. | IMAGE_SCN_LNK_INFO |
| .pdata | 异常信息 | IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ |
| .rdata | 只读的已初始化数据 | IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ |
| .reloc | 镜像重定向 | IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ | IMAGE_SCN_MEM_DISCARDABLE |
| .rsrc | 资源目录 | IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ |
| .sbss | GP-relative uninitialized data (free format) | IMAGE_SCN_CNT_UNINITIALIZED_DATA | IMAGE_SCN_MEM_READ | IMAGE_SCN_MEM_WRITE | IMAGE _SCN_GPREL The IMAGE_SCN_GPREL flag should be set for IA64 architectures only; this flag is not valid for other architectures. The IMAGE_SCN_GPREL flag is for object files only; when this section type appears in an image file, the IMAGE_SCN_GPREL flag must not be set. |
| .sdata | GP-relative initialized data (free format) | IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ | IMAGE_SCN_MEM_WRITE | IMAGE _SCN_GPREL The IMAGE_SCN_GPREL flag should be set for IA64 architectures only; this flag is not valid for other architectures. The IMAGE_SCN_GPREL flag is for object files only; when this section type appears in an image file, the IMAGE_SCN_GPREL flag must not be set. |
| .srdata | GP-relative read-only data (free format) | IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ | IMAGE _SCN_GPREL The IMAGE_SCN_GPREL flag should be set for IA64 architectures only; this flag is not valid for other architectures. The IMAGE_SCN_GPREL flag is for object files only; when this section type appears in an image file, the IMAGE_SCN_GPREL flag must not be set. |
| .sxdata | Registered exception handler data (free format and x86/object only) | IMAGE_SCN_LNK_INFO Contains the symbol index of each of the exception handlers being referred to by the code in that object file. The symbol can be for an UNDEF symbol or one that is defined in that module. |
| .text | 可执行汇编码 (free format) | IMAGE_SCN_CNT_CODE | IMAGE_SCN_MEM_EXECUTE | IIMAGE_SCN_MEM_READ |
| .tls | 线程局部存储(object only) | IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ | IMAGE_SCN_MEM_WRITE |
| .tls$ | Thread-local storage (object only) | IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ | IMAGE_SCN_MEM_WRITE |
| .vsdata | GP-relative initialized data (free format and for ARM, SH4, and Thumb architectures only) | IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ | IMAGE_SCN_MEM_WRITE |
| .xdata | Exception information (free format) | IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ |
- 接下来我们将解析Sections中比较重要的几个Section的数据
Step 3.1: 解析PE导入表(.idata)
.idata节存储着所有的导入符号,其包含下面几个内容[13]:导入目录表
Null 目录条目
DLL1 导入查找表
Null
DLL2 导入查找表
Null
DLL3 导入查找表
Null
提示/名称表
1. 导入目录表
- 导入目录表的每一个字段的含义:
| 偏移 | 大小 | 字段名 | 描述 |
|---|---|---|---|
| 0 | 4 | 导入查找表的RVA Import Lookup Table RVA (Characteristics) |
导入查找表ILT的RVA,该表包含每一个导入的名字或序号 |
| 4 | 4 | 时间/日期戳 Time/Date Stamp |
在镜像被绑定前该字段设置为0,在绑定之后该字段设置为DLL的时间/日期戳 |
| 8 | 4 | 转发链 Forwarder Chain |
第一个转发器引用的索引 |
| 12 | 4 | 名字的RVA Name RVA |
包含该DLL名字的ASCII字符串地址,该地址相对于镜像基址 |
| 16 | 4 | 导入地址表RVA Import Address Table RVA (Thunk Table) |
导入地址表IAT的RVA,在镜像被绑定之前,该表的内容与导入查找表ILT内容相同 |
2. 导入查找表ILT
- 对于PE32来说,该表是一个32位数字的数组;对于PE32+来说,该表是64位数字的数组
- 布局[13]:
| Bit(s) | Size | Bit field | Description |
|---|---|---|---|
| 31/63 | 1 | Ordinal/Name Flag | If this bit is set, import by ordinal. Otherwise, import by name. Bit is masked as 0x80000000 for PE32, 0x8000000000000000 for PE32+. |
| 15-0 | 16 | Ordinal Number | A 16-bit ordinal number. This field is used only if the Ordinal/Name Flag bit field is 1 (import by ordinal). Bits 30-15 or 62-15 must be 0. |
| 30-0 | 31 | Hint/Name Table RVA | A 31-bit RVA of a hint/name table entry. This field is used only if the Ordinal/Name Flag bit field is 0 (import by name). For PE32+ bits 62-31 must be zero. |
3. 提示/名称表:Hint/Name Table
- 布局[13]:
| 偏移 | 大小 | 字段名 | 描述 |
|---|---|---|---|
| 0 | 2 | 提示 | 导出名称指针表的索引 |
| 2 | - | 名称 | 导入名称ASCII字符串 |
| * | 0 or 1 | 填充 |
4. 导入地址表IAT
- 在镜像被绑定之前,IAT中的结构和内容与ILT相同
- 在镜像被绑定之后,IAT中的实体被重写为需要导入的32位/64位的符号地址,i.e. 该表在运行时会被PE加载器重写
解析流程:
- 在Step 2.3节中,我们解析了
NT Headers中的Data Directory字段,而该字段中就存储了Import Directory的相对虚拟地址RVA,我们需要将其转换为文件中的偏移地址 - RVA –> RAW:
- 首先应该遍历所有节区,找到该RVA属于哪一个节区
Section Headers记录了各个Section的Virtual Address和Pointer to Raw Data,该地址在文件中的偏移RAW = RVA - Section’s Virtual Address + Pointer to Raw Data(我们将该功能封装到一个函数中)- 读取并解析RAW中的数据
- 举例:我们假设导入目录表的RVA为0x1D1F4,
.idata的Virtual Address为 0x1D000且大小为0xBE7,因此该RVA在.idata段内;然后,我们根据.idata的Pointer to Raw Data值0xA800,找到该导入目录表在文件中的偏移值为0xA800+(0x1D1F4-0x1D000)= 0xA9F4 - 导入目录表实体数可以由
Import Directory的大小除以20字节得到,请注意最后一个实体为全0填充
- 在Step 2.3节中,我们解析了
处理代码:
1 | |
- 运行结果:
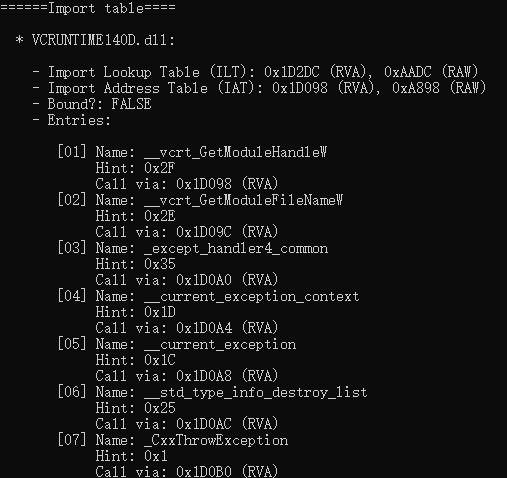
Step 3.2: 解析PE导出表(.edata)
.edata包含有关其他镜像可以通过动态链接访问的符号信息,通常包含在DLL中[14]。
| 表名称 | 说明 |
|---|---|
| 导出目录表 | 只有一行的表(与调试目录不同)。 此表指示其他导出表的位置和大小。 |
| 导出地址表 | 导出符号的 RVA 数组。 这些是可执行代码和数据节中的导出函数和数据的实际地址。 其他映像文件可以使用此表的索引(序号)或者(可选)使用与序号对应的公共名称(如果定义了公共名称)导入符号。 |
| 名称指针表 | 指向公共导出名称的指针数组,按升序排序。 |
| 序号表 | 对应于名称指针表的成员的序号数组。 对应关系按位置,因此,名称指针表和序号表的成员数必须相同。 每个序号都是导出地址表中的索引。 |
| 导出名称表 | 一系列以 null 结尾的 ASCII 字符串。 名称指针表的成员指向此区域。 这些名称是用于导入和导出符号的公共名称,它们不一定与映像文件中使用的专用名称相同。 |
1. 导出目录表
- 字段如下所示[14],其中重要的字段已加粗处理:
| 偏移量 | 大小 | 字段 | 说明 |
|---|---|---|---|
| 0 | 4 | 导出标志 | 保留,必须为 0。 |
| 4 | 4 | 时间/日期戳 | 创建导出数据的时间和日期。 |
| 8 | 2 | 主要版本 | 主版本号。 用户可以设置主要版本号和次要版本号。 |
| 10 | 2 | 次要版本 | 次版本号。 |
| 12 | 4 | 名称 RVA | 包含 DLL 名称的 ASCII 字符串的地址。 此地址相对于映像基址。 |
| 16 | 4 | 序号基 | 此映像中的导出的起始序号。 此字段指定导出地址表的起始序号。 通常设置为 1。 |
| 20 | 4 | 地址表条目 | 导出地址表中的条目数。 |
| 24 | 4 | 名称指针数 | 名称指针表中的条目数。 也是序号表中的条目数。 |
| 28 | 4 | 导出地址表 RVA | 导出地址表相对于映像基址的地址。 |
| 32 | 4 | 名称指针 RVA | 导出名称指针表相对于映像基址的地址。 表大小由“名称指针数”字段给出。 |
| 36 | 4 | 序号表RVA | 序号表相对于映像基址的地址。 |
2. 导出地址表EAT
- 可以把EAT理解为一个存放导出地址的RVA数组(4字节为一个RVA),然后根据RVA去找到具体符号的导出地址
| 偏移 | 大小 | 字段 | 说明 |
|---|---|---|---|
| 0 | 4 | 导出RVA | 加载到内存中时导出符号相对于映像基址的地址。 例如,导出函数的地址。 |
| 0 | 4 | 转发器 RVA | 指向导出节中以 null 结尾的 ASCII 字符串的指针。 此字符串必须在导出表数据目录条目给定的范围内。 |
3. 名称指针RVA
- 这个也是一个存放名称字符串RVA(4字节)的数组,这个数组是乱序的,如果要恢复其顺序,则需要使用序号表RVA中的信息
4. 序号表
序号表顺序与名称指针表顺序一致,与导出地址表顺序不一致,需要根据序号表进行恢复。
存储符号顺序的表,为16位无偏索引数组;这里需要注意的是,真正的(biased)序号等于导出目录表中的序号基 + 该16位无偏值
举个例子,序号表第一个16位为03,而相应的名称指针数组第一个RVA所表示的字符串
AboutDlgProc,序号基为01,那么上述信息可表述为序号04的函数为AboutDlgProc,其导出地址为导出地址表中第4个值9840。图解整个寻址流程:

解析流程:
先解析导出目录表,得到导出表的名称指针,并取得其名称;
其次,由于导出表项的序号是乱序的,因此我们构建了一个导出表项的实体用来存储导出表项的内容,如下:
1
2
3
4
5
6typedef struct __EXPORT_ENTRY {
WORD ordinal;
DWORD function_rva;
DWORD name_rva;
char name[100];
}EXPORT_ENTRY, *PEXPORT_ENTRY;然后,我们根据导出表项的地址表条目数[
NumberOfFunctions]来创建指定个数的导出表项实体,并根据导出目录表中的名称指针表和序号表的内容找到指定的导出表实体,并更新其字段内容;最后,将更新后的导出表实体按照ordinal的顺序打印出来
处理代码:
1 | |
- 运行结果:
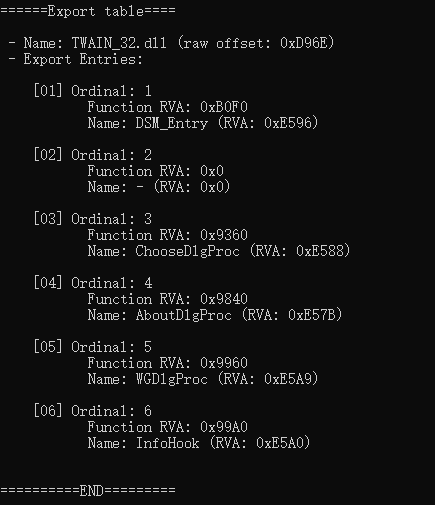
Step 3.3: 解析重定位表(.reloc)
需要重定位表的原因[7]:
在PE程序载入到内存中时,PE Loader会优先按照
ImageBase(该PE文件渴望的虚拟基地址),但就和人生一样,有时候你想要得到的不一定就能够得到,所以当该ImageBase的地址被占用的时候,该PE程序就不能加载到ImageBase的虚拟地址.text汇编码中包含有一些字符串地址、函数调用地址等,而这些地址都是由编译器根据ImageBase预先确定好的,如果PE不能加载到ImageBase所指向的虚拟地址时,上述这些地址均需要做修正(i.e. fix up)。🌰 举个例子:
1
2
3
4
5
6// 需要重定位的值013EBC98h、013ED49Ch和013E1064h
printf("Helloworld %s", "hahaha");
013E64B2 68 98 BC 3E 01 push offset string "hahaha" (013EBC98h)
013E64B7 68 9C D4 3E 01 push offset string "Helloworld %s" (013ED49Ch)
013E64BC E8 A3 AB FF FF call _printf (013E1064h)
013E64C1 83 C4 08 add esp,8
重定位表的作用[15]:
- 修复地址(仅当
ImageBase地址无法满足时)- 如何修复?
fix_up_value = origin_value - ImageBase + new_virtual_address_base
- 如何修复?
⭐ 强烈建议阅读[15]这一篇文章,很详细介绍了重定位表的作用!
- 修复地址(仅当
PE Section中重定位块[16]
- 基址重定位块
- 基址重定位类型
1. 基址重定位块
重定位表
布局:
| 偏移 | 大小 | 字段 | 描述 |
|---|---|---|---|
| 0 | 4 | 页RVA | 映像基址和页 RVA 将添加到每个偏移量,以创建必须应用基址重定位的 VA。 |
| 4 | 4 | 块大小 | 映像基址和页 RVA 将添加到每个偏移量,以创建必须应用基址重定位的 VA。 |
| 4 | 2 | 条目1 | 高4位为类型,剩余12位相较于页RVA的偏移量 |
| 6 | 8 | 条目2 | |
| … | … | … |
2.基址重定位类型
| 常数 | Value | 说明 |
|---|---|---|
| IMAGE_REL_BASED_ABSOLUTE | 0 | 跳过基址重定位。 此类型可用于填充块。 |
| IMAGE_REL_BASED_HIGH | 1 | 基址重定位会将差值的高 16 位添加到偏移量的 16 位字段。 16 位字段表示 32 位字的高值。 |
| IMAGE_REL_BASED_LOW | 2 | 基址重定位会将差值的低 16 位添加到偏移量为 16 位字段。 16 位字段表示 32 位字的低半部分。 |
| IMAGE_REL_BASED_HIGHLOW | 3 | 基址重定位会将差值的所有 32 位应用到偏移量的 32 位字段。 |
| IMAGE_REL_BASED_HIGHADJ | 4 | 基址重定位会将差值的高 16 位添加到偏移量的 16 位字段。 16 位字段表示 32 位字的高值。 32 位值的低 16 位存储在此基址重定位后的 16 位字中。 这意味着此基址重定位占用两个槽位。 |
| IMAGE_REL_BASED_MIPS_JMPADDR | 5 | 重定位解释取决于计算机类型。 当计算机类型为 MIPS 时,则基址重定位适用于 MIPS 跳转指令。 |
| IMAGE_REL_BASED_ARM_MOV32 | 5 | 仅当计算机类型为 ARM 或 Thumb 时,此重定位才有意义。 基址重定位跨连续的 MOVW/MOVT 指令对应用符号的 32 位地址。 |
| IMAGE_REL_BASED_RISCV_HIGH20 | 5 | 仅当计算机类型为 RISC-V 时,此重定位才有意义。 基址重定位适用于 32 位绝对地址的高 20 位。 |
| 6 | 保留,必须为 0。 | |
| IMAGE_REL_BASED_THUMB_MOV32 | 7 | 仅当计算机类型为 Thumb 时,此重定位才有意义。 基址重定位将符号的 32 位地址应用于连续的 MOVW/MOVT 指令对。 |
| IMAGE_REL_BASED_RISCV_LOW12I | 7 | 仅当计算机类型为 RISC-V 时,此重定位才有意义。 基址重定位适用于以 RISC-V I 型指令格式形成的 32 位绝对地址的低 12 位。 |
| IMAGE_REL_BASED_RISCV_LOW12S | 8 | 仅当计算机类型为 RISC-V 时,此重定位才有意义。 基址重定位适用于以 RISC-V S 型指令格式形成的 32 位绝对地址的低 12 位。 |
| IMAGE_REL_BASED_LOONGARCH32_MARK_LA | 8 | 仅当计算机类型为 LoongArch 32 位时,此重定位才有意义。 基址重定位适用于由两个连续指令形成的 32 位绝对地址。 |
| IMAGE_REL_BASED_LOONGARCH64_MARK_LA | 8 | 仅当计算机类型为 LoongArch 64 位时,此重定位才有意义。 基址重定位适用于由四个连续指令形成的 64 位绝对地址。 |
| IMAGE_REL_BASED_MIPS_JMPADDR16 | 9 | 仅当计算机类型为 MIPS 时,此重定位才有意义。 基址重定位适用于 MIPS16 跳转指令。 |
| IMAGE_REL_BASED_DIR64 | 10 | 基址重定位会将差值应用到偏移量的 64 位字段。 |
解析流程:
- 首先,根据
NT Header - Optional Header - Data Directory中的Base Relocation Table字段的RVA值,找到重定向表的位置 - 然后,根据基址重定位块的布局结构,依次解析相应的内容
- 最后,打印相应的内容即可
- 首先,根据
处理代码:
1 | |
Step 3.4: 解析资源表(.rsrc)
资源表是干啥的?
- 资源表存储着与GUI显示有关的元数据,也就是所谓的资源,包括光标、图标、菜单、位图等
资源表的结构:
- 三层树结构
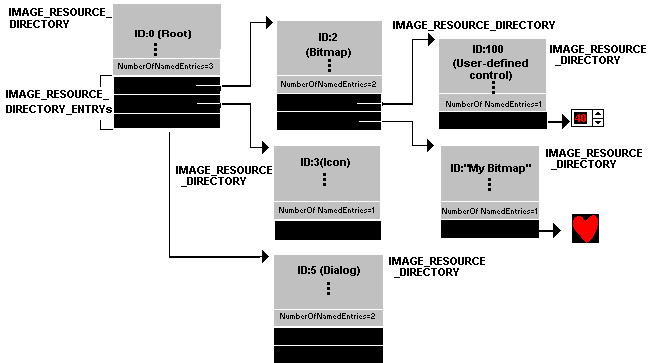
| 数据 | 说明 |
|---|---|
| 资源目录表(和资源目录条目) | 一系列表,树中每组节点对应一个表。 第一个表中列出了所有第一级(类型)节点。 此表中的条目指向第二级表。 每二级树具有相同的类型 ID,但名称 ID 不同。 第三级树具有相同的类型和名称 ID,但语言 ID 不同。 每个单独的表后紧跟目录条目,其中每个条目都有一个名称或数字标识符,以及一个指向数据描述或下一级表的指针。 |
| 资源目录字符串 | 双字节对齐的 Unicode 字符串,用作目录条目指向的字符串数据。 |
| 资源数据描述 | 由表指向的记录数组,用于描述资源数据的实际大小和位置。 这些记录是资源描述树中的叶。 |
| 资源数据 | 资源节的原始数据。 资源数据描述字段中的大小和位置信息分隔资源数据的各个区域。 |
1. 资源目录表
| Offset | 大小 | 字段 | 说明 |
|---|---|---|---|
| 0 | 4 | 特征 | 资源标志。 保留此字段供将来使用。 它当前设置为零。 |
| 4 | 4 | 时间/日期戳 | 资源编译器创建资源数据的时间。 |
| 8 | 2 | 主要版本 | 主要版本号,由用户设置。 |
| 10 | 2 | 次要版本 | 次要版本号,由用户设置。 |
| 12 | 2 | 名称条目数 | 紧跟在表之后的目录条目数,这些条目使用字符串来标识类型、名称或语言条目(取决于表的级别)。 |
| 14 | 2 | ID 条目数 | 紧跟在名称条目之后的目录条目数,这些条目对类型、名称或语言条目使用数字 ID。 |
2. 资源目录条目
| Offset | 大小 | 字段 | 说明 |
|---|---|---|---|
| 0 | 4 | 名称偏移量 | 提供类型、名称或语言 ID 条目的字符串的偏移量,具体取决于表的级别。 |
| 0 | 4 | 整数标识符 | 标识类型、名称或语言 ID 条目的 32 位整数。 |
| 4 | 4 | 数据条目偏移量 | 高位 0。 资源数据条目(叶)的地址。 |
| 4 | 4 | 子目录偏移量 | 高位 1。 较低的 31 位是另一个资源目录表的地址(下一级)。 |
3. 资源目录字符串
- 存储在最后一个资源目录条目之后和第一个资源数据条目之前
| Offset | 大小 | 字段 | 说明 |
|---|---|---|---|
| 0 | 2 | 长度 | 字符串的大小,不包括长度字段本身。 |
| 2 | 可变 | Unicode 字符串 | 可变长度的 Unicode 字符串数据,字对齐。 |
4. 资源数据条目
| Offset | 大小 | 字段 | 说明 |
|---|---|---|---|
| 0 | 4 | 数据 RVA | 资源数据区域中资源数据单位的地址。 |
| 4 | 4 | 大小 | 数据 RVA 字段指向的资源数据的大小(以字节为单位)。 |
| 8 | 4 | codepage | 用于解码资源数据中的码位值的代码页。 通常,代码页将是 Unicode 代码页。 |
| 12 | 4 | 保留,必须为 0。 |
- 解析流程:
- 按序依次解析即可
- 处理代码:
1 | |
- 运行结果:
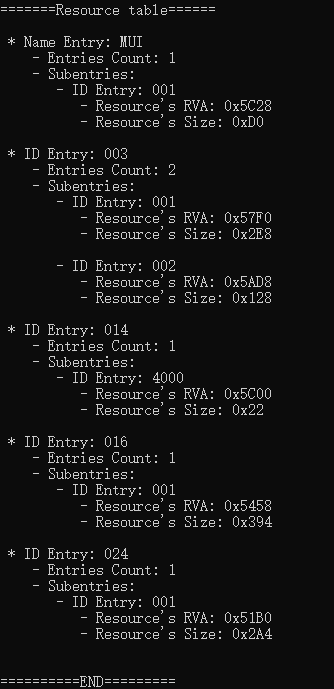
至此,我们已经基本上完成了PE32文件的解析工作。
Step 4: 解析PE32+
PE32+,i.e. 64位的PE文件
PE32与PE32+的区别:
1⃣ 第一个很显然的,
NT Header - Optional Header的Magic字段不同,对于PE32来说是10B(NT32),对于PE32+来说是20B(NT64);2⃣
PE32+的NT Header - Optional Header与PE32不同,主要体现在:PE32有一个字段为BaseofData,而PE32+没有(该4个字节给了ImageBase,因为ImageBase由4字节扩展到了8字节);PE32+中,ImageBase、SizeOfStackReserve、SizeOfStackCommit、SizeOfHeapReserve、SizeOfHeapCommit由4字节扩展到8字节,因此PE32+的NT Header64要比PE32的NT Header32多出 4*4 = 16字节(如前所述,BaseofData的字节已经分给了ImageBase)- 在
PE32+中,导入表的导入查找表ITL为64位的数组,而在PE32中,其为32位数组,这里需要区分
因此,
PE32+解析与PE32解析不同之处:NT Header不同:主要指的是Optional Header,解析时需要单独处理- 导入查找表寻址:
PE32+以64位进行寻址,而PE32以32位进行寻址
根据上述不同,我们可以很容易发动CV技能(😆)实现对
PE32+文件的解析
References:
- A dive into the PE file format - PE file structure - Part 1: Overview - 0xRick’s Blog
- A dive into the PE file format - PE file structure - Part 2: DOS Header, DOS Stub and Rich Header - 0xRick’s Blog
- A dive into the PE file format - PE file structure - Part 3: NT Headers - 0xRick’s Blog
- A dive into the PE file format - PE file structure - Part 4: Data Directories, Section Headers and Sections - 0xRick’s Blog
- A dive into the PE file format - PE file structure - Part 5: PE Imports (Import Directory Table, ILT, IAT) - 0xRick’s Blog
- A dive into the PE file format - PE file structure - Part 6: PE Base Relocations - 0xRick’s Blog
- [原创]打造自己的PE解析器-编程技术-看雪-安全社区|安全招聘|kanxue.com
- [PE-learning/PE learning at master · jmhIcoding/PE-learning (github.com)](https://github.com/jmhIcoding/PE-learning/tree/master/PE learning)
- A dive into the PE file format - LAB 1: Writing a PE Parser - 0xRick’s Blog
- Virus Bulletin :: VB2019 paper: Rich Headers: leveraging this mysterious artifact of the PE format
- VirtualAddress与VirtualSize与SizeOfRawData与PointerToRawData的关系 - zpchcbd - 博客园 (cnblogs.com)
- PE Format - Win32 apps | Microsoft Learn
- PE Format - Win32 apps | Microsoft Learn
- PE 格式 - Win32 apps | Microsoft Learn
- research32: Base relocation table
- PE 格式 - Win32 apps | Microsoft Learn