关于QEMU和AFL-QEMU模式那些事
关于QEMU和AFL-QEMU模式那些事
1. QEMU是什么?
- QEMU(Quick EMUlator)是一个仿真和模拟虚拟环境的开源软件,其本质上还是一个软件,通过动态翻译实现模拟[1]。
- 软件虚拟化
- 跨平台
- 仿真多种架构的处理器
动态翻译
- 以模拟x86下的指令为例,动态翻译的基本思想就是把每一条x86指令切分为若干条微操作,而每条微操作都是由QEMU中的一段简单的C代码来实现
- QEMU的动态翻译后端是TCG[2],Tiny Code Generator
CPU 状态优化
- 状态记录在翻译块(Translation Block,TB)中
- 如果状态发生改变,那么新TB将会生成,而之前的TB将不再使用直到状态与之前的TB相匹配
- e.g. x86 SS-堆栈段寄存器 DS-数据段寄存器 ES-附加段寄存器 为0时,将不再生成一个新的段基址
块直接链接
执行完每一个翻译块之后,QEMU根据模拟的PC和CPU状态信息来找到下一个基本块(基于哈希表?)
- 如果下一个块还没被翻译过,那么将载入一个新的块
- 否则,跳转到下一个已经翻译过的块中
对于模拟的PC已知的情况下,QEMU直接patch一个TB:直接跳转
自修改代码和翻译代码非法检查
- 当一个TB生成后,相应的页是写保护的。如果对该页进行写操作,那么QEMU将使得所有已翻译的块失效,并重新启用写权限
- 给定一个页维护一个由每一个TB块构成的链表
异常处理
longjmp():FPE- SIGSEGV、SIGBUS
MMU 模拟
2. AFL QEMU模式
2.1 安装
- 安装相关依赖:
1 | |
- 将
build_qemu_support.sh脚本的下载地址修改为https://download.qemu.org/qemu-2.10.0.tar.xz,原地址404无法访问 - 运行脚本!
1 | |
错误1:如果出现下面的报错信息,则将build_qemu_support.sh脚本的第148-150行的./configure末尾添加一个--python=/path/to/python_bin即可:
1 | |
e.g.
1 | |
错误2:如果出现下面的报错信息,原因是glibc wrapper更改所致,解决办法是将下述补丁添加到patches/syscall.path中:
1 | |
Patch(syscall1.patch):
1 | |
重新运行脚本!
Now, just enjoy it!:happy:
2.2 使用
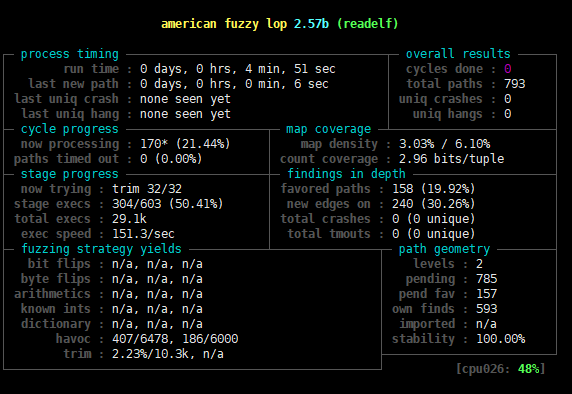
使用方法很简单,仅需在afl-fuzz中添加-Q参数即可。例如,对ubuntu操作系统自带的readelf进行模糊测试,执行如下命令:
1 | |
2.3 原理[4]
qemu在执行一个程序时,从被执行程序的入口点开始对基本块翻译并执行,为了提升效率,qemu会把翻译出来的基本块存放到cache中,当qemu要执行一个基本块时首先判断基本块是否在cache中,如果在cache中则直接执行基本块,否则会翻译基本块并执行。
在cpu-exec.diff中,afl-qemu-cpu-inl.h是AFL为适用于QEMU的forkserver和覆盖率统计的头文件:
2.3.1 AFL_QEMU_CPU_SNIPPET2
AFL_QEMU_CPU_SNIPPET2被植入到cpu-exec.c的cpu_tb_exec()函数中,该函数用于执行一个TB,并根据需要修复CPU状态;
1 | |
AFL_QEMU_CPU_SNIPPET2:这里的思路和AFL基于汇编的插桩一致,就是在QEMU执行每一个TB之前,判断当前的PC是否为入口点(afl_entry_point在 elfload.c中被赋值)。如果是入口点,则在此处获取共享内存区域地址,并启用forkserver。请注意,这里的afl_forkserver其实是一个死循环,也就是整个elf程序在这里被阻塞,直到fuzzer有数据需要程序运行时才会fork出一个子进程1
2
3
4
5
6
7#define AFL_QEMU_CPU_SNIPPET2 do { \
if(itb->pc == afl_entry_point) { \
afl_setup(); \
afl_forkserver(cpu); \
} \
afl_maybe_log(itb->pc); \
} while (0)afl_entry_point:elfload.c可以看作是包含QEMU载入ELF文件相关操作的一个c文件,其中load_elf_image()函数用以将ELF镜像载入到地址空间中。这里的info->entry其实就是ELF文件入口地址,其值为ehdr->e_entry + load_bias。注意到这里有一个load_bias,这个值其实上是ELF文件加载到内存中的一个偏差值。- 在
elfload.c处将afl_entry_point赋值为ELF文件的入口地址,然后在翻译每个TB之前判断该TB是否为初始块,如果为初始块,则在此处设置forkserver,这里的想法与AFL的插桩逻辑是一致的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32--- qemu-2.10.0-rc3-clean/linux-user/elfload.c 2017-08-15 11:39:41.000000000 -0700
+++ qemu-2.10.0-rc3/linux-user/elfload.c 2017-08-22 14:33:57.397127516 -0700
@@ -20,6 +20,8 @@
#define ELF_OSABI ELFOSABI_SYSV
+extern abi_ulong afl_entry_point, afl_start_code, afl_end_code;
+
/* from personality.h */
/*
@@ -2085,6 +2087,8 @@
info->brk = 0;
info->elf_flags = ehdr->e_flags;
+ if (!afl_entry_point) afl_entry_point = info->entry; //
+
for (i = 0; i < ehdr->e_phnum; i++) {
struct elf_phdr *eppnt = phdr + i;
if (eppnt->p_type == PT_LOAD) {
@@ -2118,9 +2122,11 @@
if (elf_prot & PROT_EXEC) {
if (vaddr < info->start_code) {
info->start_code = vaddr;
+ if (!afl_start_code) afl_start_code = vaddr;
}
if (vaddr_ef > info->end_code) {
info->end_code = vaddr_ef;
+ if (!afl_end_code) afl_end_code = vaddr_ef;
}
}
if (elf_prot & PROT_WRITE) {
2.3.2 AFL_QEMU_CPU_SNIPPET1
AFL_QEMU_CPU_SNIPPET1被植入到QEMU的tb_find()函数中。tb_find()函数用于在哈希表中寻找当前PC所对应的TB,如果没找着该TB,则调用tb_gen_code()来进行动态翻译,之后便附加上了AFL_QEMU_CPU_SNIPPET1所对应的代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25#define AFL_QEMU_CPU_SNIPPET1 do { \
afl_request_tsl(pc, cs_base, flags); \
} while (0)
...
/* This code is invoked whenever QEMU decides that it doesn't have a
translation of a particular block and needs to compute it. When this happens,
we tell the parent to mirror the operation, so that the next fork() has a
cached copy. */
static void afl_request_tsl(target_ulong pc, target_ulong cb, uint64_t flags) {
struct afl_tsl t;
if (!afl_fork_child) return;
t.pc = pc;
t.cs_base = cb;
t.flags = flags;
if (write(TSL_FD, &t, sizeof(struct afl_tsl)) != sizeof(struct afl_tsl))
return;
}这里将当前TB的信息保存到结构体
afl_tsl中,并将该信息发送回fuzzer。而afl_wait_tsl()函数就是用来等待fork子进程通过管道传递回afl_tsl的信息:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27static void afl_wait_tsl(CPUState *cpu, int fd) {
struct afl_tsl t;
TranslationBlock *tb;
while (1) {
/* Broken pipe means it's time to return to the fork server routine. */
/* 注意到这里是一个死循环,不断地获取TB的相关信息,那这里在什么时候break呢?子进程杀死或者关闭了管道之后就会break */
if (read(fd, &t, sizeof(struct afl_tsl)) != sizeof(struct afl_tsl))
break;
/* 下面这部分的代码是不是有点多余?因为在cpu-exec.c中其实已经存在有相同的处理逻辑了 */
tb = tb_htable_lookup(cpu, t.pc, t.cs_base, t.flags);
if(!tb) {
mmap_lock();
tb_lock();
tb_gen_code(cpu, t.pc, t.cs_base, t.flags, 0);
mmap_unlock();
tb_unlock();
}
}
close(fd);
}这里的
struct afl_tsl t就是象征性的获取一下,在后续的流程中并没有使用,这里其实就是监控子进程状态的一个处理过程。
2.3.3 afl_maybe_log()
1 | |
- 🤔
cur_loc是PC,注意到这里的索引值为(cur_loc >> 4) ^ (cur_loc << 8):代码注释中说指令地址可能对齐了,因此对该索引值进行了修改。这里其实关键的问题在于指令地址空间远大于哈希位图的大小,换言之很容易发生碰撞。我们这里假设PC值(32位)为0x04001234,假设下一次PC值(32位)为0x04011234,那么如果不进行上述的修改,与MAP_SIZE与的结果是相同的,因此会造成很严重的哈希位图碰撞问题,而且这个由于PC值本身空间范围很大,因此这种哈希位图碰撞问题格外的严重。所以这里必须进行相关的转换操作来避免PC值的碰撞,从而有效区分不同PC值(i.e.不同的基本块)。
2.4 改进
- 参考资料[4]中针对AFL中QEMU模式存在的问题进行了阐述,如下:
在原始的
AFL qemu版本中获取覆盖率的方式是在每次翻译基本块前调用afl_maybe_log往afl-fuzz同步覆盖率信息,这种方式有一个问题就是由于qemu会把顺序执行的基本块chain一起,这样可以提升执行速度。但是在这种方式下有的基本块就会由于chain的原因导致追踪不到基本块的执行,afl的处理方式是禁用qemu的chain功能,这样则会削减qemu的性能(🤔 应该不太会影响qemu的性能吧,但确实会额外添加一些AFL本身的执行)。
- 我们在第一节中阐述的QEMU特性中,其中有一个就是
Direct block chaining。其实就是说,原本能够顺序在一起的基本块,比如A->B->C,QEMU可以将这三个块链起来,从而整合为一个块A’。然而这样的操作会导致AFL跟踪基本块执行的不精确,因此AFL禁用了QEMU的chain功能 - 那AFL++的QEMU模式如何进行了改机呢?
- 将统计覆盖率插桩的代码插入到每个翻译的基本块前面,=>代码:
1 | |
这里需要注意的是gen_helper_afl_maybe_log和gen_helper_afl_maybe_log_trace这两个函数,这两个函数用于创建一个TCG的call调用,并调用afl_maybe_log或afl_maybe_log_trace这两个函数。简而言之,这两个函数就是用于生成调用AFL进行覆盖率统计的相关函数,这些函数定义在accel/tcg/translate-all.c中:
1 | |
include/exec/helper-head.h:
1 | |
include/exec/helper-gen.h:
1 | |
afl_gen_trace()用于在每个基本块前插入afl_maybe_log或afl_maybe_log_trace的函数调用,跟踪程序的覆盖情况。
1 | |
与afl_request_tsl()相匹配的是afl_wait_tsl(),该函数检查当前缓存的TB,如果是新TB,则判断该TB的PC是否合法。这里源码注释中描述到:
1 | |
也就是说,如果子进程请求翻译一个没有在父进程中映射的内存块时,这会导致在gen_intermediate_code()函数以及后续相关联的程序中发生SEGV的错误因此应当避免缓存这类块,因此这里做了一个过滤操作。
此外,该版本的改进还额外支持了AFL中的persistent模式,此节不再详细介绍,感兴趣的读者可以阅读[qemuafl的源码](AFLplusplus/qemuafl: This fork of QEMU enables fuzzing userspace ELF binaries under AFL++. (github.com))
3. 小结
- QEMU本质上就是用软件去模拟不同平台下的程序运行的一个虚拟机
- AFL/AFL++对QEMU源码进行了适当的魔改,使其能够与模糊器进行通信并完成相关覆盖率的统计或其他功能
- 不建议使用AFL提供的一键安装QEMU的脚本,建议使用AFL++中魔改过后的QEMU版本:AFLplusplus/qemuafl: This fork of QEMU enables fuzzing userspace ELF binaries under AFL++. (github.com)
🔗 Reference:
- https://github.com/lishuhuakai/qemu_reading/tree/main/Document/qemu-0.1.6
- [Translator Internals — QEMU documentation](https://www.qemu.org/docs/master/devel/tcg.html#:~:text=QEMU is a dynamic translator,simple while achieving good performances.)
- Bellard, Fabrice. “QEMU, a fast and portable dynamic translator.” USENIX annual technical conference, FREENIX Track. Vol. 41. 2005.
- 基于qemu和unicorn的Fuzz技术分析 - 先知社区 (aliyun.com)
- Linux中ELF文件启动过程 - 怎么可以吃突突 - 博客园 (cnblogs.com)