深入浅出AFL插桩
AFL插桩剖析
I. 前置知识
- 编译器产生可执行文件的流程如下图1、2所示(以gcc编译器为例,clang同理):
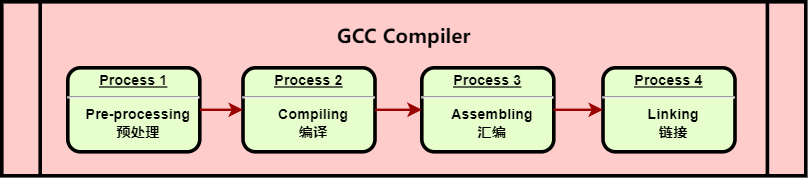
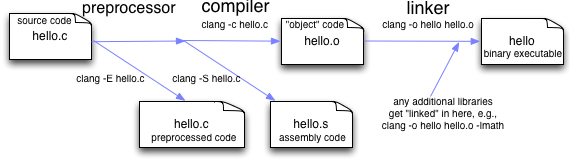
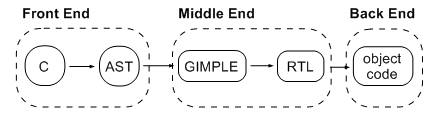
- 主流的编译器【图1中第二个阶段】包括三个组件:前端、中间端和后端 [1]
- 前端:读取源文件并对其进行分析,通常是将源码转化为标准抽象语法树(AST)
- 中间端:进行源码优化,通常是使用生成的某种中间表示【GCC中是GIMPLE/RTL;Clang中是IR】,并根据该中间表示进行优化
- 后端:使用优化后的中间表示来生成对应目标架构的汇编代码
1. GCC
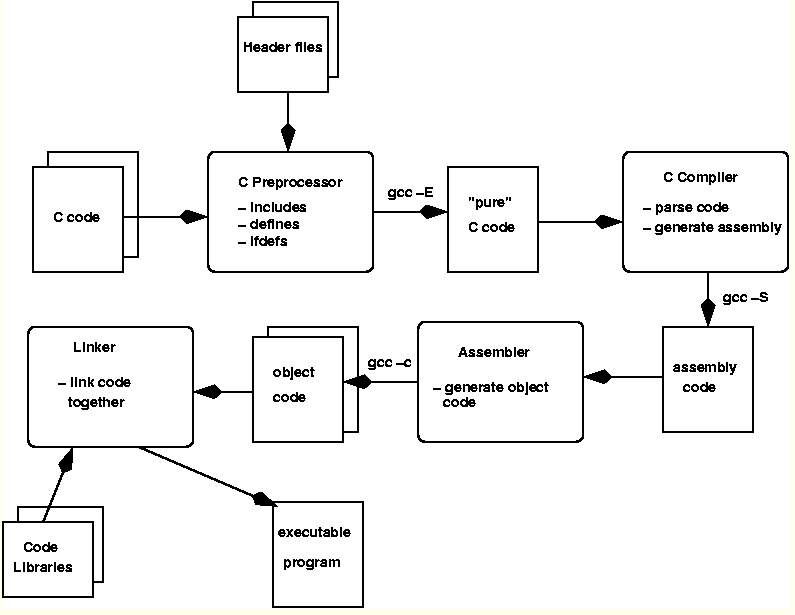
- GCC 4.1架构图:
四个阶段
1 | |
前端分析
对源代码进行预处理、语法分析、语义分析,同时会生成抽象语法树AST
parse the source code ➡ 即将源代码转化为有意义的数据(有意义是针对机器来说的),表示我们可读的源代码究竟想要表达啥
🤔 GCC本身无法输出生成的AST [2],这里我们展示GCC编译过程中生成的CFG [3] :
- 源代码:
1 | |
- 产生AST对应的
.dot文件:
1 | |
- 使用
dot程序将main函数对应.dot转化为可视图:
1 | |
中间端优化
- GCC中间端包括两个部分:GIMPLE 和 RTL
GIMPLE:
派生自GCC GENERIC(也是一种中间表示;最初,不同的GCC前端会生成依赖于架构的树表示,而GENERIC是作为与平台无关的树表示而引入的,以简化前端开发过程。GENERIC的目标是生成GIMPLE [5])
three-address表示:
- 将GENERIC表达式拆成不超过3个操作数的元组(除了函数调用)
引入暂存器来保存计算复杂表达式所需的中间值,GENERIC中使用的控制结构降级为条件跳转,词法作用域被移除,而异常区域则被转换为边上的异常区域树
使用一个”gimplifier”将GENERIC转化为GIMPLE
包括”High GIMPLE“和”Low GIMPLE“
- High GIMPLE包含一些容器语句,如词法范围和嵌套表达式,派生自前端AST树或GENERIC,然后基于High GIMPLE生成Low GIMPLE
- Low GIMPLE则显示所有控制和异常表达式的隐含跳转
C和C++前端直接从前端AST树转化为GIMPLE,而不是转化为GENERIC
使用标志
-fdump-tree-gimple来生成类C的表示
✋ 说白了,GIMPLE就是干了两件事:
1⃣ 删除高级结构,如for,while循环【用goto和跳转替换】
2⃣ 简化表达式(通过引入临时变量)
⚠ 可以在Low GIMPLE实现GIMPLE层级的Pass!
🌰 if (a || b) stmt; ==>
1 | |
GCC生成GIMPLE:
Low GIMPLE:
1 | |
High GIMPLE:
1 | |
RTL:
- 寄存器转换语言 Register Transfer Language,与汇编语言很接近
- 表示一个具有无限数量寄存器的抽象机器,结构类似于Lisp和C语言的混合
- 在生成RTL代码后,GCC编译器在将其转换到汇编语言之前进行了不同的底层优化 [7]
- 由于RTL表示的生成和优化的程序在编译过程的后端,这意味着它依赖于硬件,而不包含程序的所有信息
✋ 说白了,RTL就是干了两件事:
1⃣ 将GIMPLE转化为与硬件相关的RTL语言
2⃣ 在RTL基础上进行底层优化
⚠ 同样的,我们也可以实现基于RTL层级的Pass!
🌰 b = a - 1 ==>
1 | |
- RTL中的一些优化Passes:
| Name |
|---|
| RTL generation |
| Loop optimization |
| Jump bypassing |
| If conversion |
| Instruction combination |
| Register movement |
| Instruction scheduling |
| Register allocation |
| Final |
GCC生成RTL:
1 | |
后端生成
- 后端为指定的目标平台生成汇编代码
GCC生成目标平台汇编代码:
1 | |
2. Clang
四个阶段
- 与GCC类似,不再赘述
前端分析
- Clang前端管线:

预处理:
- C/C++预处理器在词法分析之前执行,主要功能是
- 展开宏
- 展开包含文件
- 根据各种以#开头的预处理器指示略去部分代码
词法分析:
- 处理源代码的文本输入,将语言结构分解为一组单词和标记,去除注释、空白、制表符等
- clang词法分析输出结果:
1 | |
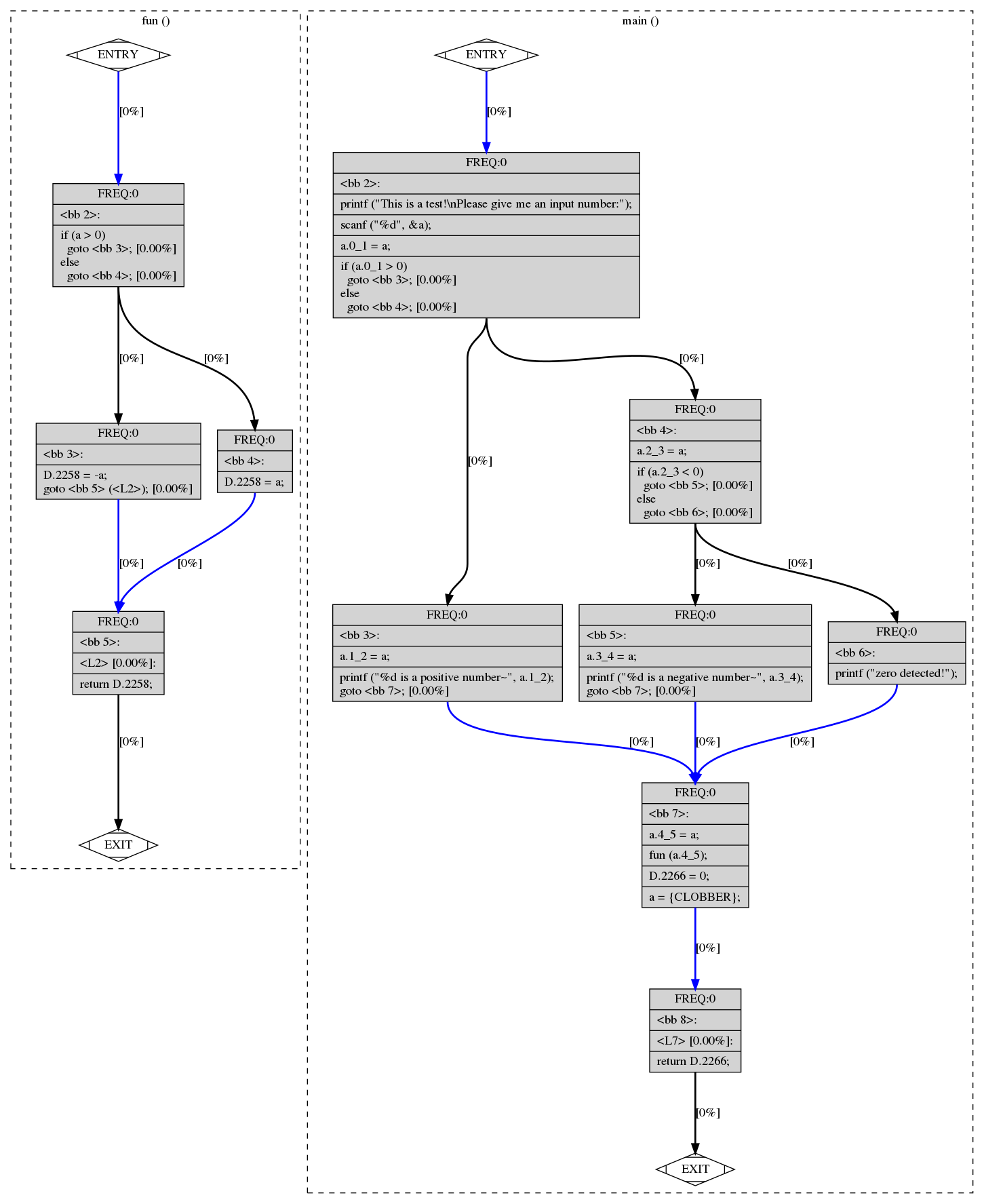
例如,在fun()[Line 4-6] 函数内的if语句高亮输出是:
1 | |
语法分析:
将词法分析产生的标记流作为输出,输出语法树(AST)
一个AST节点表明声明、语句和类型
语法解析器接受并处理在词法阶段生成的标记序列,每当发现一组要求的标记在一起的时候,此时会生成一个AST节点
如每当发现一个标记tok::kw_if时,就会调用
ParseIfStatement()函数处理if语句体中的所有标记,并为它们生成所必须的孩子AST节点和一个IfStmt根节点// lib/Parse/ParseStmt.cpp ... case tok::kw_if: // C99 6.8.4.1: if-statement return ParseIfStatement(TrailingElseLoc); case tok::kw_switch: // C99 6.8.4.2: switch-statement return ParseSwitchStatement(TrailingElseLoc); ...1
2
3
4
5
6
7
8
9
10
* Clang并不在解析之后遍历AST,而是在AST节点生成过程中即时检查类型
* 语法分析**识别解析错误**
* Clang生成**AST**树:
```bash
$ clang -fsyntax-only -Xclang -ast-dump afl_inst_test.c
# or clang -cc1 -ast-dump afl_inst_test.c [9]
AST树的可视化界面:
1 | |
生成LLVM IR
经过词法分析和语义分析的联合处理之后,Clang会调用
CodeGenAction()编译AST以生成LLVM IR前端流水线结束!
中间端优化[11]
LLVM中间表示IR是连接前端和后端的中枢,让LLVM能够解析多种源语言,为多种目标生成代码
前端产生IR,后端也接收IR
引入IR的出发点:1⃣ 解决不同语言源代码的差异性; 2⃣ 便于生成不同平台相异的机器指令集
- 通用性
- 高级IR能够让优化器轻松提炼出原始源代码的意图;低级IR让编译器能够更容易生成为特定硬件优化的代码
IR的三种等价形式:
- 驻留内存的表示(指令类等)
- 磁盘上以空间高效方式编码的位表示(bitcode文件)
- 磁盘上的人类可读文本表示(LLVM汇编文件)
IR的工作流图:
Clang生成IR:
1 | |
- 生成bitcode:
1 | |
- 生成汇编表示:
1 | |
- 汇编LLVM IR汇编文本以生成bitcode:
1 | |
- 反编译bitcode为IR汇编:
1 | |
- llvm-extract工具提取IR函数、全局变量,还能从IR模块中删除全局变量:
1 | |
后端生成[12]
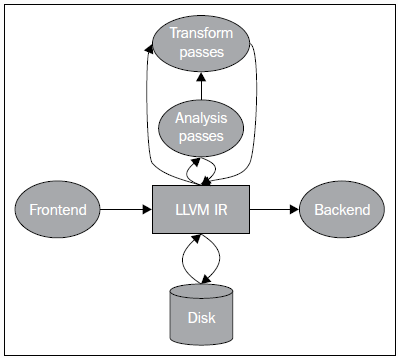
- 后端主要的步骤就是将LLVM IR转换为目标汇编代码,具体步骤如图8所示:
简要描述上述代码生成的各个阶段:
指令选择(instruction selection):
1⃣ 将内存中的IR表示变换为目标特定的selectionDAG节点,每一个DAG表示单一基本块的计算
你可以使用debug版本的llc来生成selectionDAG节点信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
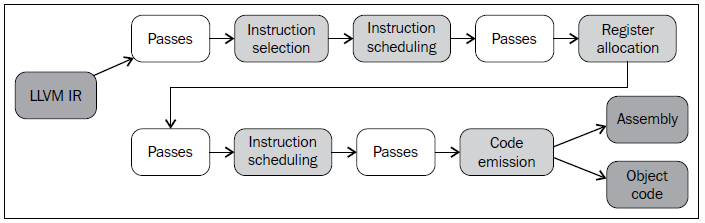
15$ /llvm-project/build/bin/llc -debug sum.bc # 这里使用debug版本的clang!
...
SelectionDAG has 18 nodes:
t0: ch = EntryToken
t6: i64 = Constant<0>
t2: i32,ch = CopyFromReg t0, Register:i32 %0
t8: ch = store<ST4[%a.addr]> t0, t2, FrameIndex:i64<0>, undef:i64
t4: i32,ch = CopyFromReg t0, Register:i32 %1
t10: ch = store<ST4[%b.addr]> t8, t4, FrameIndex:i64<1>, undef:i64
t11: i32,ch = load<LD4[%a.addr](dereferenceable)> t10, FrameIndex:i64<0>, undef:i64
t12: i32,ch = load<LD4[%b.addr](dereferenceable)> t10, FrameIndex:i64<1>, undef:i64
t13: i32 = add nsw t11, t12
t16: ch,glue = CopyToReg t10, Register:i32 %eax, t13
t17: ch = X86ISD::RET_FLAG t16, TargetConstant:i32<0>, Register:i32 %eax, t16:1
...此外,你可以执行下面的命令来生成selectionDAG图:
1
$ /llvm-project/build/bin/llc -view-dag-combine1-dags sum.bc -fast-isel=false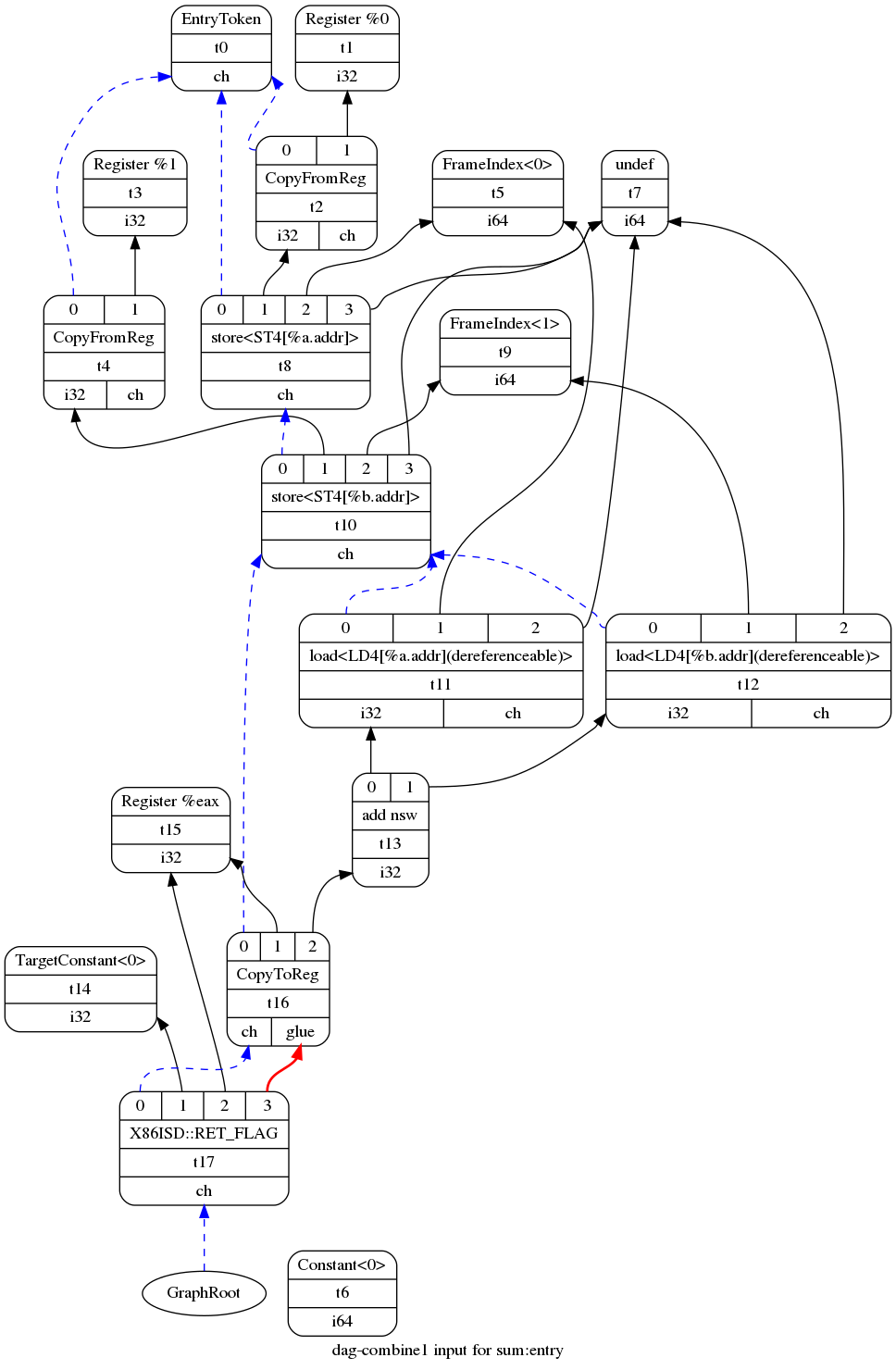
图9 sum函数的SelectionDAG图 2⃣ 利用模式匹配将目标无关的节点转换为目标特定的节点,而指令选择的算法是局部的,每次作用SelectionDAG(基本块)的实例
可以执行一下命令生成指令选择后的SelectionDAG图:
1
$ /llvm-project/build/bin/llc -view-sched-dags sum.bc -fast-isel=false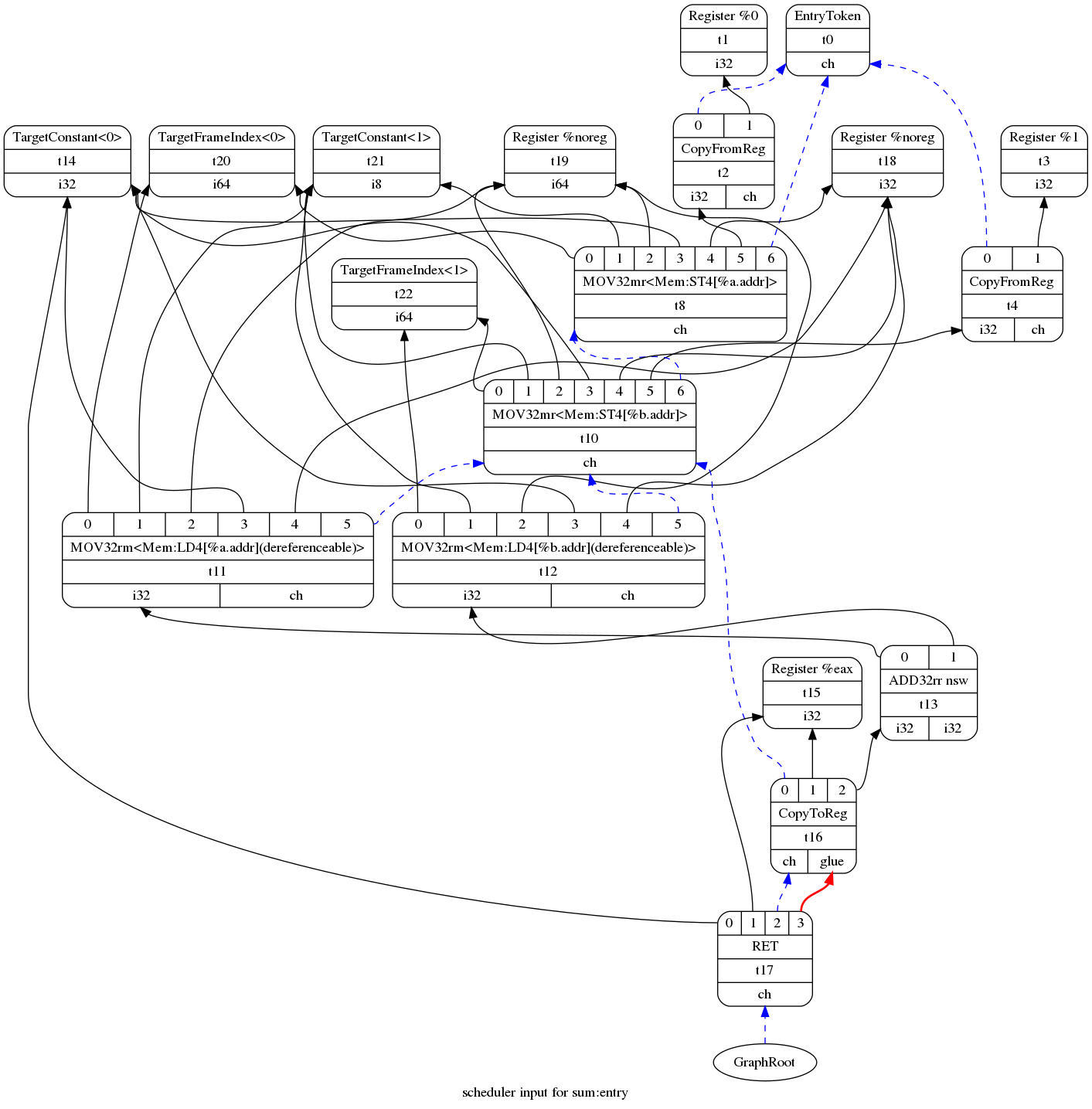
图10 指令选择后的sum函数的SelectionDAG图 由上图我们可以看到,在指令选择之后,原先DAG图中的add节点被替换成ADD32rr,X86ISD::RET_FLAG被替换为RET,load被替换为MOV32rm,store被替换为MOV32mr
指令调度(instruction scheduling):
- 指令延迟表:根据具体硬件信息来提高指令级并行,从而提高在计算机上指令流水线的性能 [14]
- 风险检测与识别
- 调度单元
1
$ /llvm-project/build/bin/llc -view-sunit-dags sum.bc -fast-isel=false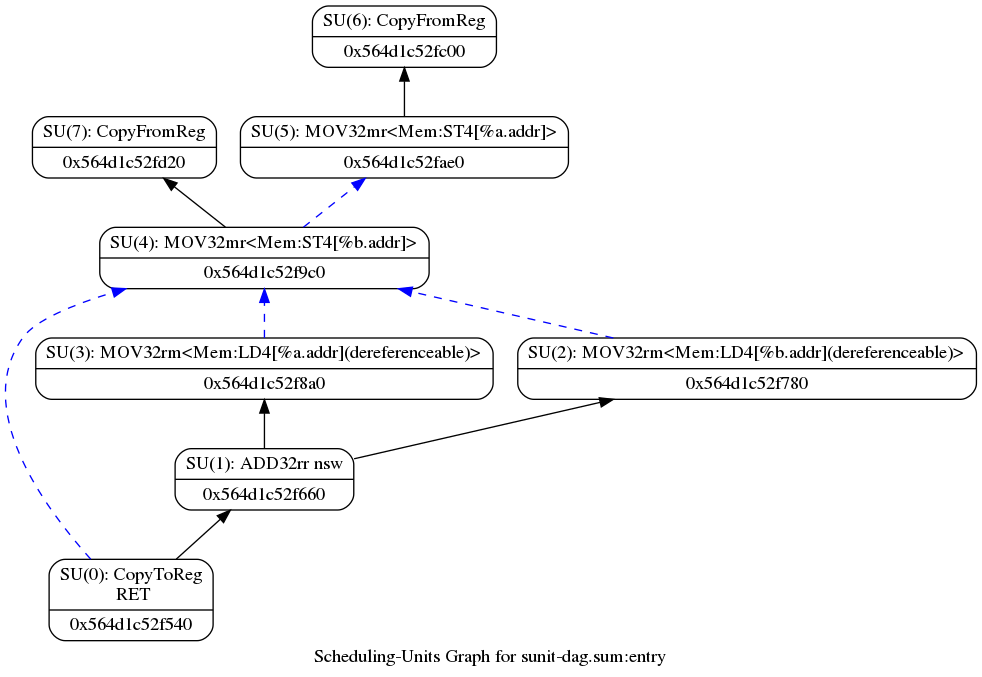
图11 调度单元图 寄存器分配(Register allocation)
作用在机器指令上:
- 在指令调度之后,InstrEmitter Pass会被运行,它将
SDNode格式转换为MachineInstr格式 - 该表示相较于IR指令更接近实际的目标指令
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23$ /llvm-project/build/bin/llc -march=sparc -print-machineinstrs sum.bc
...
# After Instruction Selection:
# Machine code for function sum: IsSSA, TracksLiveness
Frame Objects:
fi#0: size=4, align=4, at location [SP]
fi#1: size=4, align=4, at location [SP]
Function Live Ins: %i0 in %0, %i1 in %1
%bb.0: derived from LLVM BB %entry
Live Ins: %i0 %i1
%1:intregs = COPY %i1; IntRegs:%1
%0:intregs = COPY %i0; IntRegs:%0
%3:intregs = COPY %1; IntRegs:%3,%1
%2:intregs = COPY %0; IntRegs:%2,%0
STri %stack.0.a.addr, 0, %0; mem:ST4[%a.addr] IntRegs:%0
STri %stack.1.b.addr, 0, %1; mem:ST4[%b.addr] IntRegs:%1
%4:intregs = LDri %stack.0.a.addr, 0; mem:LD4[%a.addr](dereferenceable) IntRegs:%4
%5:intregs = LDri %stack.1.b.addr, 0; mem:LD4[%b.addr](dereferenceable) IntRegs:%5
%6:intregs = ADDrr killed %4, killed %5; IntRegs:%6,%4,%5
%i0 = COPY %6; IntRegs:%6
RETL 8, implicit %i0
...- 在指令调度之后,InstrEmitter Pass会被运行,它将
基本任务:将无限数量的虚拟寄存器转换为有限的物理寄存器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21$ /llvm-project/build/bin/llc -print-after=greedy sum.bc
# *** IR Dump After Greedy Register Allocator ***:
# Machine code for function sum: NoPHIs, TracksLiveness
Frame Objects:
fi#0: size=4, align=4, at location [SP+8]
fi#1: size=4, align=4, at location [SP+8]
Function Live Ins: %edi in %0, %esi in %2
0B %bb.0: derived from LLVM BB %entry
Live Ins: %edi %esi
16B %3:gr32 = COPY %esi; GR32:%3
32B %1:gr32 = COPY %edi; GR32:%1
80B MOV32mr %stack.0.a.addr, 1, %noreg, 0, %noreg, %1; mem:ST4[%a.addr] GR32:%1
96B MOV32mr %stack.1.b.addr, 1, %noreg, 0, %noreg, %3; mem:ST4[%b.addr] GR32:%3
112B %7:gr32 = MOV32rm %stack.0.a.addr, 1, %noreg, 0, %noreg; mem:LD4[%a.addr] GR32:%7
144B %7:gr32 = ADD32rm %7, %stack.1.b.addr, 1, %noreg, 0, %noreg, implicit-def dead %eflags; mem:LD4[%b.addr] GR32:%7
160B %eax = COPY %7; GR32:%7
176B RETQ implicit %eax
# End machine code for function sum.- 寄存器合并器、虚拟寄存器重写和目标钩子
II. AFL如何进行插桩?
原生AFL有两种插桩方式
基于编译器生成的汇编文件的插桩
- 关键文件有两个,分别是
afl-gcc.c和afl-as.c afl-gcc/g++/clang/clang++/gcj:编译器(gcc、clang、gcj)的一个wrapper ➡ 编译器产生汇编文件afl-as:汇编器(as)的一个wrapper ➡ 对编译器产生的汇编文件进行插桩,然后调用as生成目标文
图解:
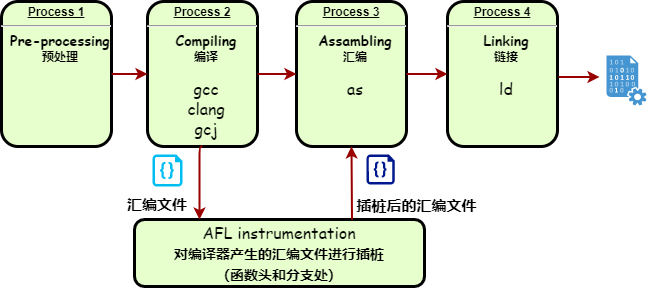
图12 基于编译器的AFL插桩流程 - 关键文件有两个,分别是
基于LLVM模式的插桩
- 关键文件即
llvm_mode文件夹下的所有文件
- 关键文件即
a. 基于编译器汇编文件的插桩
1. afl-gcc.c
是主流编译器的一个wrapper,根据具体调用的
afl-xxx编译器名来进行分流:afl-xxx编译器都是afl-gcc的一个软链接,如下所示1
2
3
4
5$ ll afl-gcc afl-g++ afl-clang afl-clang++
lrwxrwxrwx 1 chan chan 7 Nov 3 23:52 afl-clang -> afl-gcc*
lrwxrwxrwx 1 chan chan 7 Nov 3 23:52 afl-clang++ -> afl-gcc*
lrwxrwxrwx 1 chan chan 7 Nov 3 23:52 afl-g++ -> afl-gcc*
-rwxrwxr-x 1 chan chan 22976 Nov 3 23:52 afl-gcc*
与
afl-as的结合使用:使用gcc/clang-B选项来指定汇编器路径,即AFL本身的路径换言之,
afl-gcc本质上还是调用的原来的编译器,只不过将汇编器替换为了afl-as(而afl-as的主要作用就是进行插桩!)源码解析:
find_as():在环境变量AFL_PATH【AFL本身的路径】提供”假的”GNU汇编器,即AFL_PATH/as;或者根据argv[0]的路径进行派生。📓 注:这里的as本身也是afl-as的一个软链接,如下所示:1
2
3$ ll afl-as as
-rwxrwxr-x 1 chan chan 37544 Nov 3 23:52 afl-as*
lrwxrwxrwx 1 chan chan 6 Nov 3 23:52 as -> afl-as*edit_params():构造新的命令行选项,即将argv中的选项拷贝到cc_params中,同时提供一些必要的编辑:首先对
argv[0]进行匹配,即进行分流:afl-clang=>clang;afl-clang++=>clang++;afl-g++=>g++;afl-gcj=>gcj;afl-gcc=>gcc然后将
argv中其他的选项拷贝到cc_params,在这过程中,对一些选项进行处理:-B将被覆写-integrated-as、-pipe、将被删除- 如果遇到
-fsanitize=address或-fsanitize=memory时,将asan_set标志变量设置为1,将选项添加到cc_params - 如果遇到
FORTIFY_SOURCE设置项,则将fortify_set标志变量设置为1,将选项添加到cc_params# 编译器的一种安全检测机制,防溢出
然后添加-B选项,即
-B as_path,as_path为find_as()函数设置的汇编器路径。接着进行5个判断:如果是
clang_mode,添加-no-integrated-as选项以避免使用clang集成的汇编器如果设置了环境变量
AFL_HARDEN,则添加-fstack-protector-all[15] 和-D_FORTIFY_SOURCE=2如果
asan_set == 1,则将环境变量AFL_USE_ASAN设置为1;否则,判断是否设置了AFL_USE_ASAN或AFL_USE_MSAN,并检查相应的互斥性和添加相应的选项(-U_FORTIFY_SOURCE和-fsanitize=address/memory)如果设置了环境变量
AFL_DONT_OPTIMIZE,那么将不进行优化操作,否则将添加下述选项:选项 含义 -g 全局绑定,主要用于debug -O3 O3级优化 -funroll-loops 避免优化器展开循环,其主要目的有两个:
1⃣ 便于对循环体的边进行跟踪
2⃣ 避免循环体内其他边的数量爆炸(循环展开后会产生冗余边)-D__AFL_COMPILER=1 # 不是编译器本身的选项
在ChangeLog中,该变量用来指示该程序是在afl-gcc / afl-clang / afl-clang-fast下构建的,并且允许自定义的优化-DFUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION=1 - 如果设置了环境变量
AFL_NO_BUILTIN,那么将不进行相关函数的内置替换(即汇编处将使用call相关函数,对于AFL插桩来说,这将引入额外的开销,因此默认进行builtin)。具体来说,通过添加下述选项来实现:选项 -fno-builtin-strcmp -fno-builtin-strncmp -fno-builtin-strcasecmp -fno-builtin-strncasecmp -fno-builtin-memcmp -fno-builtin-strstr -fno-builtin-strcasestr
execvp():执行构造的命令行,即cc_params。该命令行将调用编译器生成相应的可执行文件,正如前所述,-B指定了afl的汇编器进行插桩操作,因此下面我们将详细介绍afl-as.c的具体流程。
2. afl-as.c
由前所述,
afl-gcc/clang/g++/clang++/gcj通过-B参数指定了AFL的汇编器路径,那么在gcc/g++/clang/clang++/gcj生成目标文件/可执行文件的过程中,将使用afl-as作为其编译器,而afl-as本身也是as一个wrapper:- 先对编译器产生的汇编文件进行插桩
- 然后再调用系统的
as来生成相应的机器码
💭 但是这样一来无法对
afl-as进行调试?经过对
afl-as的简单分析,我们可以先通过afl-gcc -S生成汇编文件,然后将汇编文件放置在tmp目录下1
2
3
4
5
6
7$ afl-gcc -S afl_inst_test.c -o afl_inst_test.s
afl-cc 2.57b by <lcamtuf@google.com>
afl_inst_test.c: In function ‘main’:
afl_inst_test.c:12:2: warning: ignoring return value of ‘scanf’, declared with attribute warn_unused_result [-Wunused-result]
scanf("%d", &a);
^~~~~~~~~~~~~~~
$ mv afl_inst_test.s /tmp使用
afl-as对上述产生的汇编文件进行汇编操作:1
2
3$ /home/chan/some_c_test/AFLAPI/afl-as -o afl_inst_test.o /tmp/afl_inst_test.s
afl-as 2.57b by <lcamtuf@google.com>
[+] Instrumented 4 locations (64-bit, non-hardened mode, ratio 100%).:happy:由上述的结果,我们可以看出该汇编文件已经成功插桩了。但这里我们无法捕获到插桩后的汇编文件,因此需要对
afl-as进行debug。
源码解析:
一些局部变量:inst_ratio_str => inst_ratio [默认为100,插桩率 0~100];sanitizer [是否启用ASAN/MSAN?]
srandom():置时间种子,种子由当前时间的秒、微秒和进程pid异或得到edit_params():构造汇编所使用的命令行环境变量
TMPDIR可以自定义临时文件夹,此外,环境变量TEMP和TMP同样有相同的功能,否则tmp_dir默认为”/tmp“,这也是我们之前将汇编文件放置在tmp目录下的原因 ✋然后将原
argv【前argc-1个选项】拷贝到as_params[]中。这里检测原命令行中是否出现"--64"/"--32"=> 将use_64bit标志变量相应的设置为1 / 0⚠ 注:在调用
afl-as时,必须将输入文件放置在最后,即afl-as -o xxx.o xxx.s✔,afl-as xxx.s -o xxx.o❌input_file = argv[argc - 1] // xxx.s判断
input_file是否在/tmp或/var/tmp,如果不再则将pass_thru置为1【这会导致后面不进行插桩操作】modified_file为插桩后汇编文件,这里根据时间和pid随机分配一个名字,如/tmp/.afl-4270-1669033267.s然后将
modified_file添加到as_params最后,作为汇编器的输入文件!
如果设置了环境变量
AFL_USE_ASAN或AFL_USE_MSAN,将sanitizer置为1,且将插桩率inst_ratio除以3❓ 这里为啥要将
inst_ratio除以3?源码注释中作者这样描述:
“在使用ASAN编译时,没有一个特别优雅的方法跳过ASAN特有的分支,但可以通过插桩率上进行补偿…”
见解:1⃣ ASAN会引入由ASAN所导致的特定分支,而如前所述,ASAN插桩是在编译过程完成的,而AFL在编译器生成的汇编基础上进行插桩,因此会对ASAN本身特定的分支进行插桩。概率插桩(33%)在一定程度上能够反映软件的真实覆盖率大小。
2⃣ ASAN的插桩是重量级的,因此ASAN引入的边可能会导致比特位图碰撞性提升,而概率插桩能够解决这一问题
add_instrumentation():对汇编文件进行插桩(分支处插桩 + 相关调用函数)如果
input_file文件不能打开,则将stdin作为输入;modified_file作为输出文件;【分支处插桩】读取
input_file中的每一行,并做一系列的判断,其主要找到三个位置:- 函数头:
1
2
3
4
5
6
7
8
9function_name:
.LFB23:
.file 1 "afl_inst_test.c"
.loc 1 3 0
.cfi_startproc
.LVL0:
.loc 1 5 0
# <<======== instrumentation here
movl %edi, %eax- jx/jxx的两条分支:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36# branch 1
.LVL7:
.loc 1 14 0
movl 4(%rsp), %edx
cmpl $0, %edx
jg .L11
# <<======== instrumentation here
.loc 1 16 0
jne .L12
# <<======== instrumentation here
...
# branch 2
.L11:
.cfi_restore_state
.LVL10:
.LBB26:
.LBB27:
.loc 2 104 0
# <<======== instrumentation here
leaq .LC2(%rip), %rsi
movl $1, %edi
xorl %eax, %eax
call __printf_chk@PLT
.LVL11:
jmp .L7
.LVL12:
.L12:
.LBE27:
.LBE26:
.LBB28:
.LBB29:
# <<======== instrumentation here
leaq .LC3(%rip), %rsi
movl $1, %edi
xorl %eax, %eax
call __printf_chk@PLT🤔 汇编中
.开头标识的意义 [16]:1⃣
.loc:**Line Of Code [-g?]**,格式为.loc 文件序号 行序号 [列] [选项],在上示例中,.loc 1 14 0表示file 1:afl_inst_test.c,第14行第0列 [17]2⃣ GCC使用
.L用于本地标签本地符号是以某种本地标签前缀开头的任何符号,默认情况下,ELF系列的本地标签前缀是“.L”
本地符号在汇编器中被定义和使用,但它们通常不被保存在目标文件中。因此在调试时它们是不可见的。可以使用
-L选项保留目标文件中的本地符号 [18]e.g.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23>/tmp$ as -c -L afl_inst_test.s # you can also use `as --keep-locals -c afl_inst_test.s`
>/tmp$ nm a.out
>0000000000000000 T fun
U _GLOBAL_OFFSET_TABLE_
U __isoc99_scanf
>000000000000006d t .L11
>0000000000000082 t .L12
>0000000000000097 t .L13
>...
>/tmp$ as -c afl_inst_test.s
>/tmp$ nm a.out
>0000000000000000 T fun
U _GLOBAL_OFFSET_TABLE_
U __isoc99_scanf
>0000000000000000 r .LC0
>0000000000000000 r .LC1
>0000000000000003 r .LC2
>000000000000001c r .LC3
>0000000000000035 r .LC4
>0000000000000000 T main
U __printf_chk
U __stack_chk_fail
>/tmp$3⃣
.L前缀(是DWARF调试信息,不重要):1
2
3
4
5#define FUNC_BEGIN_LABEL "LFB"
#define FUNC_END_LABEL "LFE"
#define BLOCK_BEGIN_LABEL "LBB"
#define BLOCK_END_LABEL "LBE"
ASM_GENERATE_INTERNAL_LABEL (loclabel, "LVL", loclabel_num);LFB:函数开始; LFE:函数结束;LBB:块开始;LBE:块结束;LVL:尚不知
详见 [19]
【相关调用函数的附加】最后,将
main_payload_64或main_payload_32添加到汇编文件的末尾处。至此,所有的插桩过程均已完成!
execvp():fork一个子进程执行构造的新的as_params,即对插桩后的汇编文件进行汇编操作。最后删除临时文件 [modified_file],至此,汇编任务完成
3. afl-as.h (桩代码解析)
- 主要有两个桩代码:1⃣
trampoline_fmt_64/trampoline_fmt_32;2⃣main_payload_64/main_payload_32;
1⃣ trampoline_fmt_64/trampoline_fmt_32(以64位为例):
- 汇编码:
1 | |
- 上述汇编码调用了
__afl_maybe_log(%rcx[i.e.当前分支对应的随机数])来记录边的情况
2⃣ main_payload_64/main_payload_32(以64位为例):
- 汇编码主要包括10个函数,分别是:
__afl_maybe_log、__afl_store、__afl_return、__afl_setup、__afl_setup_first、__afl_forkserver、__afl_fork_wait_loop、__afl_fork_resume、__afl_die、__afl_setup_abort __afl_maybe_log、__afl_store、__afl_return:
1 | |
__afl_setup:
1 | |
__afl_setup_first、__afl_forkserver、__afl_fork_resume和__afl_die:
1 | |
__afl_setup_abort:
1 | |
__afl_maybe_log()伪代码:
1 | |
🤔 上述插桩残留一个问题:
父进程的主要作用是维持一个fork-server,那它与AFL之间通过一个管道进行通信,但通信的具体细节是啥呢?
4. 与AFL通信
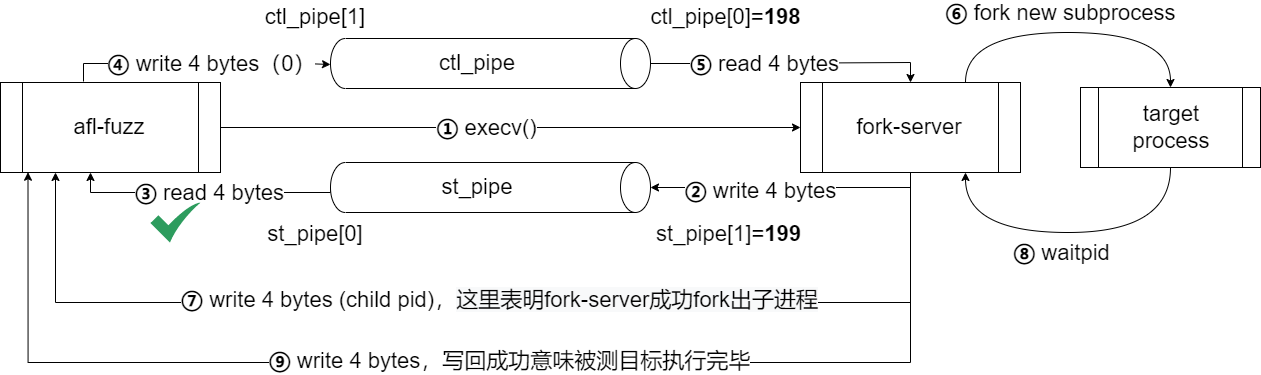
在AFL中,
afl-fuzz中init_forkserver()是初始化forkserver的函数:- 在该函数中,
afl-fuzz会fork出一个子进程,并为管道分配新的fd(198 ==> 控制管道ctl_pipe[0],199 ==> 状态管道st_pipe[0])。而这个子进程execv一个被测程序,这个被测程序(i.e. fork-server)在调用第一个__afl_maybe_log()函数时,首先会向状态管道写入4字节的任意数据,然后将在while循环中的第一个read(198, &_afl_temp, 4)处阻塞,等待AFL-fuzzer发来信息; - 而在
afl-fuzz父进程中,通过读取状态管道4字节的数据来判断是否成功启用fork-server
- 在该函数中,
在AFL中,
run_target()将通知fork-server出一个新的子进程来跑模糊测试生成的测试用例:afl-fuzz进程将4个字节的超时时间写入到控制管道fork-server在读取到4个字节(0)之后,将停止阻塞。然后fork()出一个新的子进程来跑实际的被测目标,pid将通过状态管道送回给afl-fuzzer,然后收集覆盖率信息。这里fork-server将这读入的四字节0用于waitpid()的第二个参数,然后等待子进程执行完毕。子进程执行完毕之后,fork-server再向状态管道写入4字节,表明被测程序执行完毕afl-fuzz根据fork出来的被测程序pid的结束信号和覆盖率信息做进一步的分析处理
流程图如下所示。其中 ①→②→③ 为创建
fork-server的过程,④→⑤→⑥→⑦→⑧→⑨ 为一次完整的run_target()的过程。
b. 基于LLVM的插桩
- afl-clang-fast、afl-clang-fast++
- 基于LLVM Pass实现
1. afl-clang-fast.c
是clang和clang++的一个wrapper,根据具体调用的afl-clang-fast(++)来区分
- afl-clang-fast++是afl-clang-fast的一个软链接,如下所示:
1
2
3$ ll afl-clang-fast afl-clang-fast++
-rwxrwxr-x 1 chan chan 24608 Nov 28 18:36 afl-clang-fast*
lrwxrwxrwx 1 chan chan 14 Nov 28 18:36 afl-clang-fast++ -> afl-clang-fast*与llvm Pass(
afl-llvm-pass.so)结合使用:使用-Xclang让clang运行用户自定义的Pass- 与
afl-gcc的区别:Pass在编译器运行时进行插桩,而afl-gcc对编译器运行结束后生成的汇编文件进行插桩
- 与
源码解析:
find_obj():寻找afl-llvm-rt.o目标文件,并将AFL路径保存到obj_path变量中edit_params():构造新的编译命令行选项cc_params,将argv中的选项拷贝到cc_params中,同时提供一些必要的编辑:首先对
argv[0]进行匹配,即进行分流:afl-clang-fast++=>clang++afl-clang-fast=>clang如果使用
trace_pc模式,则在cc_params后追加-fsanitize-coverage=trace-pc-guard;否则追加两个选项:-Xclang -load(加载包含插件注册表的动态库)和-Xclang obj_path/afl-llvm-pass.so。此外,还要额外追加一个-Qunused-arguments[20] 选项来静默关于未使用参数的警告。将
argv[]中其他的选项拷贝到cc_params,在此期间将更新一些变量值
选项 变量 -m32、armv7a-linux-androideabi bit_mode = 32 -m64 bit_mode = 64 -x <language> (将输入文件试为某一语言的文件) x_set = 1 ==> “-x none” -fsanitize=address、-fsanitize=memory asan_set = 1 FORTIFY_SOURCE fortify_set = 1 -Wl,-z,defs 不追加到 cc_params中-Wl,–no-undefined 不追加到 cc_params中- 后面追加的一些选项与
afl-gcc相似,不再赘述。这里需要注意的是,如果使用了trace pc模式,AFL_INST_RATIO将不可使用。afl-clang-fast使用-D选项向cc_params追加了一些隐式的#define,分别是:
值 __AFL_HAVE_MANUAL_CONTROL=1 __AFL_COMPILER=1 FUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION=1 __AFL_LOOP(_A)=({ static volatile char *_B __attribute__((used)); _B = (char*) “##SIG_AFL_PERSISTENT##”; __attribute__((visibility("default"))) int _L(unsigned int) __asm__("__afl_persistent_loop"); _L(_A); }) __AFL_INIT()=do { static volatile char *_A __attribute__((used)); _A = (char*) “##SIG_AFL_DEFER_FORKSRV##”; __attribute__((visibility("default"))) void _I(void) __asm__("__afl_manual_init"); _I(); } while (0) - 最后,根据
bit_mode向cc_params后追加对应的目标文件 [ 默认为afl-llvm-rt.o,32位afl-llvm-rt-32.o,64位afl-llvm-rt-64.o]
execvp():执行构造的命令行,即cc_params。该命令行通过-Xclang运行Pass,然后将afl-llvm-rt.o目标文件链接到最终生成的afl-clang-fast。🤔 这里有个问题,
afl-llvm-pass.so.cc的作用显而易见,就是构造执行Pass插桩的动态链接库,但目标文件afl-llvm-rt.o的作用是什么呢?
2. afl-llvm-pass.so.cc
生成执行插桩Pass的动态链接库
AFLCoverage::runOnModule:用于执行转换(插桩)1⃣ 创建两个全局变量:
__afl_area_ptr用于保存共享内存区域的地址;__afl_prev_loc用于存放前一个基本块ID右移一位的值2⃣ 遍历所有基本块BB:
- 随机生成一个基本块ID值
cur_loc - 载入全局变量
__afl_prev_loc - 载入全局共享内存区域指针
__afl_area_ptr,计算值cur_loc xor __afl_prev_loc - 更新比特位图:将上述计算值作为索引,在
__afl_area_ptr中寻址,让对应的字节值+1 - 更新
__afl_prev_loc的值:__afl_prev_loc = cur_loc >> 1
- 随机生成一个基本块ID值
registerAFLPass用来注册该AFLCoverage Pass类
3. afl-llvm-rt.o.c
该文件的主要作用有:
1⃣ 在被测目标程序执行之前调用
__afl_auto_init()初始化函数:- 使用
__attribute__((constructor(CONST_PRIO)))关键字,让该函数在被测目标程序调用main()函数之前执行 [21] - 调用
__afl_manual_init()函数:__afl_map_shm()函数用来获取共享内存区域地址__afl_start_forkserver()函数用来启动fork-server,其整体逻辑与图13一样,此处不再赘述【注:这里是死循环,用来fork子进程】
2⃣ Persistent mode
在源文件中设置
__AFL_LOOP(int)后启用如前所述,
afl-clang-fast在编译目标程序时,会使用-D选项引入一个#define __AFL_LOOP(_A)的宏定义,该宏定义会将源代码中的__AFL_LOOP(int)替换为__afl_persistent_loop(int)【通常__AFL_LOOP()与while()结合使用】int __afl_persistent_loop(unsigned int max_cnt):- 在第一次调用该函数时,该函数会清空
__afl_area_ptr的值,即清空覆盖率跟踪位图信息(在达到__AFL_LOOP()之前的所有覆盖率信息都将被清空),然后将__afl_area_ptr[0]置为1,__afl_prev_loc置为0 - 在非第一次调用该函数时(如与
while()循环一起使用时),说明前一轮的覆盖率信息已经统计完成,在轮数不为0的情况下,首先raise(SIGSTOP),表示程序暂停,然后fork-server的waitpid将直接返回,程序仍在运行中,然后该覆盖率信息将被AFL处理,同时生成下一个测试用例投喂给目标程序 fork-server再接收到AFL生成了新的测试用例并需要运行目标程序的消息之后,由于先前的程序处于暂停状态,fork-server将不会fork()一个新的子进程,而是向之前暂停的子进程发送SIGCONT(继续运行)的信号,然后又回到上一步的循环中,直到循环次数结束- 循环次数结束后,
__afl_area_ptr会重定向到一个虚假的位图__afl_area_initial中,避免收集__AFL_LOOP()后面执行的代码覆盖率
- 在第一次调用该函数时,该函数会清空
代码:
1
2
3
4
5while(__AFL_LOOP(1000)) {
// AFL只会统计该循环中的代码覆盖率
// 优点:速度快,避免频繁的调用程序的初始化操作;
// 能够通过一定数量输入的投喂使得程序到达某一状态,因此可以覆盖到更深层次的代码(这对于网络程序来说具有奇效)
}流程图:
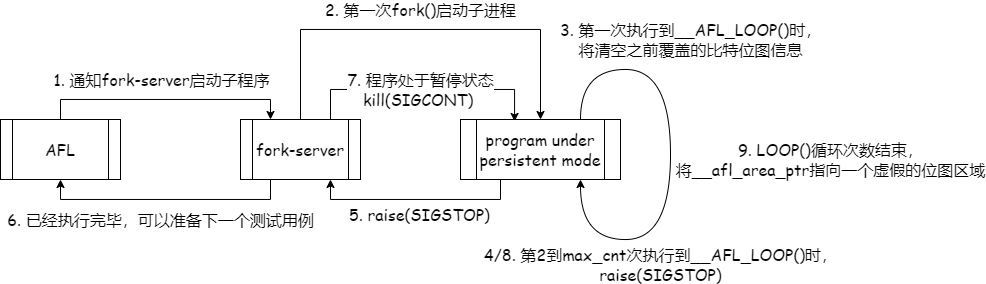
图14 persistent mode流程图
3⃣ Deferred forkserver模式:
由环境变量
__AFL_DEFER_FORKSRV控制,用于控制在何时启动forkserver,避免一些长时间的初始化操作影响吞吐量__AFL_INIT(); // the forkserver will be raised here! // do something ...
4⃣ trace_pc_guard模式:
trace_pc_guard模式对所有的边进行插桩,插桩值为guard
__sanitizer_cov_trace_pc_guard_init(start, stop):- 替换每个
trace_pc处的guard值(随机数),不进行插桩的guard值设置为0
- 替换每个
__sanitizer_cov_trace_pc_guard(guard):- 更新共享内存数据:对比特位图中索引为
guard的字节+1
- 更新共享内存数据:对比特位图中索引为
trace_pc_guard编译过程中遇到的问题:
makefile 中定义
AFL_TRACE_PC = 1如果输出如下显示,则将afl-clang-fast.c 的第133行替换为:
c_params[cc_par_cnt++] = "-sanitizer-coverage-level=0";clang (LLVM option parsing): Unknown command line argument ‘-sanitizer-coverage-block-threshold=0’. Try: ‘clang (LLVM option parsing) -help’
clang (LLVM option parsing): Did you mean ‘-sanitizer-coverage-pc-table=0’?
- 使用
Reference
gcc - AST from c code with preprocessor directives - Stack Overflow
GCC GENERIC - Advanced course on compilers - Aalto University Wiki
GCC RTL - Advanced course on compilers - Aalto University Wiki
linker - How to link C++ object files with ld - Stack Overflow
LLC -view-dag-combine1-dags - Beginners - LLVM Discussion Forums
c - What are .LFB .LBB .LBE .LVL .loc in the compiler generated assembly code - Stack Overflow
Common Function Attributes - Using the GNU Compiler Collection (GCC)