AFL++源码浅析
AFL++源码解析
afl-fuzz.c
main函数
rand_set_seed()设置四个种子:afl->init_seed, afl->rand_seed[0-2]- while循环对选项进行判断,支持的选项有:
"+Ab:B:c:CdDe:E:hi:I:f:F:g:G:l:L:m:M:nNOo:p:RQs:S:t:T:UV:WXx:YZ":
| 选项 | 描述 |
|---|---|
-i dir |
测试用例输入目录 |
-o dir |
模糊测试发现的输出目录 |
-p schedule |
能量调度计算一个种子表现分数:fast(默认),explore,exploit,seek,rare,mmopt,coe,lin,quad |
-f file |
目标程序读入数据的位置(默认:stdin 或 @@) |
-t msec |
每轮的超时时间(默认 1000 ms),添加’+’来自动计算超时时间 |
-m megs |
子进程内存限制(0 MB,0=无限制 [默认]) |
-A |
使用仅二进制插桩(ARM CoreSight mode) |
-O |
使用仅二进制插桩(FRIDA mode) |
-Q |
使用仅二进制插桩(QEMU mode) |
-U |
使用基于unicorn的插桩(Unicorn mode) |
-W |
使用基于qemu的Wine插桩(Wine mode) |
-X |
使用VM模糊测试(NYX mode - standalone mode) |
-Y |
使用VM模糊测试(NYX mode - multiple instances mode) |
-g minlength |
设置生成模糊测试输入的最小长度(默认1) |
-G maxlength |
设置生成模糊测试输入的最大长度(默认 1*1024*1024) |
-D |
启用确定性模糊测试(一个队列仅进行一次) |
-L minutes |
使用MOpt(imize)模式并设置进入pacemaker模式的时间限制(无新发现的时间),0=立即,-1=立即并进行正常变异 |
-c program |
指定一个编译的二进制来启用CmpLog。如果使用QEMU/FRIDA或模糊测试目标已使用CmpLog编译,那么使用-c 0. |
-l cmplog_opts |
CmpLog配置值(如“2AT”):1=小文件, 2=大文件(默认),3=所有文件,A=算法求解,T=transformational求解 |
-Z |
序列队列选择,而不是随机权重 |
-N |
不解除模糊测试文件的链接 |
-n |
无插桩模糊测试(non-instrumented mode) |
-x dict_file |
模糊器字典 |
-s seed |
为RNG使用一个固定的种子 |
-V seconds |
模糊测试特定的时间之后结束 |
-E execs |
执行一个近似多少次执行后终止模糊测试 |
-M/-S id |
分布式模式,-M auto-sets -D,-Z(使用-d禁用-D)并不进行trimming |
-F path |
同步到一个外部模糊器队列目录(需要-M,最多可以指定32次) |
-T text |
在屏幕上展示text banner |
-I command |
当一个新的crash发现时,执行一个特定的命令或脚本 |
-C |
crash探索模式 |
-b cpu_id |
将模糊测试进程绑定到特定的CPU核心上(0-…) |
-e ext |
模糊测试输入文件的文件扩展(如果需要的话) |
-h |
展示选项信息 |
setup_signal_handlers()设置信号句柄check_asan_opts()检查asan选项:获取环境变量ASAN_OPTIONS并检查相关选项设置是否正确- afl->schedule记录了afl能量调度模式,默认为fast;如果afl-schedule基于fast实现,则需要为其动态分配内存用于记录AFLFast调度信息
check_crash_handling()确保核心转储不会进入一个程序中。
1 | |
check_cpu_governor():检查CPU governor,主要检查linux内核CPU调频是否存在问题。save_cmdline():将命令行保存到afl->orig_cmdline变量中check_if_tty:检查是否是tty。具体通过ioctl(1, TIOCGWINSZ, &ws)获取终端信息来判断是否为tty终端get_core_count():获取CPU核心数setup_dirs_fds():创建相关文件描述符bind_to_free_cpu():构建绑定到核心的进程列表init_count_class16():由count_class_lookup8桶构造count_class_lookup16数组setup_custom_mutators():设置用户自定义的变异器,详见AFL++自定义变异器setup_cmdline_file():将命令行保存到default/cmdline文件中read_testcases():从输入目录中读取所有测试用例,然后将其放置在队列中pivot_inputs():为输出目录的输入测试用例创建硬链接,选择一个好的名字并将其转移到新队列实体中setup_stdio_file():为模糊测试数据创建输入文件,默认为default/.cur_input,如果包含扩展名,则为default/.cur_input.(扩展名)check_binary():对PATH路径进行搜索来寻找目标二进制,同时确保其不是一个shell脚本,同时检查其是否有一个有效的ELF头并判断是否进行了插桩(通过环境变量__AFL_SHM_ID进行判断)。此外,该函数还检查一些环境变量并设置相关参数setup_testcase_shmem():设置模糊测试输入的共享内存,并通过环境变量__AFL_SHM_FUZZ_ID传递给forkserverload_auto():自动载入生成的extrasdeunicode_extras():有时候extras中的字符串在内部转化为unicode码,因此模糊测试时需要将看起来像unicode的字符串进行unicode解码操作dedup_extras():从载入的extras中删除重复(在多个文件载入时可能会发生这个问题)将
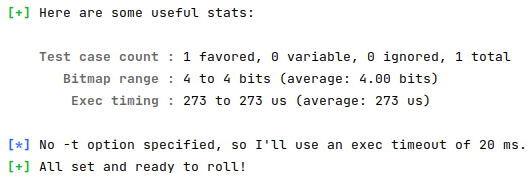
virgin_bits、virgin_tmout和virgin_tmout数组的比特全部设置为1perform_dry_run():对所有测试用例预运行以确保程序按期望那样运行。该操作仅在初始输入阶段完成并只执行一次cull_queue():精简队列【贪心算法】,通过遍历top_rated[]中的queue实体,提取出能够发现新边的实体,并将其标记为favored。在下次遍历队列时,这些favored实体能够获得更多执行模糊测试的机会。show_init_stats():打印出初始状态,如下图所示:
save_auto():自动保存生成的extras
模糊测试主循环
1 | |
afl->cycle_schedules为周期更换调度算法的标志,更换调度算法后,需要重新计算队列所有实体的分数runs_in_current_cycle为表示当前循环的变量create_alias_table():创建别名表,允许权重随机选择(开销较大)static inline void *afl_realloc(void **buf, size_t size_needed):- 该函数为realloc的一个wrapper,其主要是确保在调用该函数后,buf的真实大小始终 > size_needed,避免频繁调用realloc。该buf size使用指数增长。
1
2
3
4
5
6
7
8struct afl_alloc_buf {
/* The complete allocated size, including the header of len
* AFL_ALLOC_SIZE_OFFSET */
size_t complete_size;
/* ptr to the first element of the actual buffer */
u8 buf[0];
};afl->alias_table、afl->alias_probability为struct afl_alloc_buf型指针,分别表示别名表和相应的概率- 接下来进行一系列的概率计算,其结果更新到
afl->alias_probability中
select_next_queue_entry():基于别名采样算法选择下一个队列实体
fuzz_one()
该fuzz_one()函数位于
afl-fuzz-one.c中,该函数实际上为一个wrapper,旨在实现MOPT。原始的fuzz_one()函数被重命名为fuzz_one_original()这里使用
afl->limit_time_sig参数值进行fuzz_one()函数的分流:afl->limit_time_sig由-L参数确定,-L参数的minute传递给afl->limit_time_puppet,该值仅能是0到2000000 或 -1afl->limit_time_puppet == -1➡afl->limit_time_sig = -1&&afl->limit_time_sig = 0;否则afl->limit_time_sig = 1
/* 伪代码 */ if (afl->limit_time_sig <= 0) { // afl->limit_time_sig = 0 表示不启用 MOPT fuzz_one_original(); } if (afl->limit_time_sig != 0) { // 启用 MOPT if (afl->limit_time_sig <= 0) pilot_fuzzing(); else if (afl->key_module == 1) core_fuzzing(); else if (afl->key_module == 2) pso_updating(); }
fuzz_one_original()
从队列中选择一个实体,并进行一段时间的模糊测试。返回0表示成功进行模糊测试,返回1表示跳过或放弃模糊测试
如果设置了用户自定义的变异器,即
afl->custom_mutators_count = 1,那么用户自定义的变异器将决定跳过哪些测试用例根据
afl->pending_favored标志来判断在队列中是否有新的favored、没有模糊测试过的种子,如果有且当前种子已经被模糊测试过或不是favored,那么有99%概率跳过该种子的模糊测试;如果afl->pending_favored标志为false,那么如果当前模糊测试为插桩模式、当前种子不是favored且种子队列数>10,如果队列周期大于1且当前种子未进行过模糊测试(新周期内产生的种子,但不是favored的),75%的概率跳过;否则有95%的概率跳过对该种子的模糊测试queue_testcase_get():首先判断是否启用缓存,如果未启用缓存,则从文件中读入数据并返回;否则,判断该测试用例是否已经缓存到内存中,如果已被缓存,则直接从内存中取出即可,否则将该测试用例缓存到内存中,返回指针afl->queue_cur->testcase_buf。如果当前测试用例无法满足放入缓存的条件(超过缓存缓存大小/超过最大缓存数),则进行一个自适应缓存冲突算法,具体来说:
afl->q_testcase_cache_size:当前种子测试用例缓存大小afl->q_testcase_max_cache_size:能够缓存的最大种子测试用例大小afl->q_testcase_cache_count:当前已缓存种子个数afl->q_testcase_max_cache_entries:能够缓存的最大的种子数afl->q_testcase_max_cache_count:当目前为止的最大缓存数afl->q_testcase_cache[]:该数组维护了一个已缓存的种子列表
一共有两种情况,1⃣ 【该操作只进行一次】 是缓存种子数未达到最大种子缓存数,仅仅是缓存空间不够了,那么将缓存的最大种子数
q_testcase_max_cache_entries设置为 max(afl->q_testcase_cache_count, afl->q_testcase_max_cache_count) + 1,然后重新分配afl->q_testcase_cache【该数组记录被缓存的种子】的空间(当前缓存种子数/历史最大种子缓存数+2)。在这种情况下,缓存空间溢出,还需要将当前缓存空间的一个或多个缓存替换为当前种子测试用例,见情况2🤔 由于测试用例过大,可能不需要这么大的缓存种子数(因为较大的测试用例会很快填充缓存空间),这本身也是一种自适应的缓存配置。
2⃣ 缓存种子数即将达到了最大种子缓存数(即仅剩下最后一个缓存空位),那么在
afl->q_testcase_cache数组中不是空且不是指向当前种子的位置,释放该种子的缓存,即afl->q_testcase_cache[tid]->testcase_buf,并更新相关变量值。反复进行上述操作,直到缓存能够放下当前种子为止。然后将文件二进制数据读入到
q->testcase_buf,并更新相关变量值。calibrate_case():校准一个新的测试用例,在处理输入目录时完成,以便在早期警告有问题的测试用例,同时在发现新路径时检测变量行为等trim_case():如果是插桩模式、trim_done未进行过且启用了trim,则对测试用例进行修剪操作。修剪操作的目的是尽可能减少输入测试用例的大小,因为测试用例的大小会影响模糊测试的速度。该操作进行指定步长的删除操作,然后将删除后的测试用例进行运行,如果trace_bits相同(删除后的测试用例和原测试用例触发相同的程序状态,但删除后的测试用例具有更小的大小),则将该删除操作写入到测试用例文件中。注:这里需要同时更新缓存的数据。calculate_score():根据执行时间、bitmap大小、handicap(后来者允许运行更长的时间)、种子深度、能量调度(决定factor)、MOPT模式的一些指标等计算种子得分确定性变异阶段:如果给定了
-d,则跳过确定性变异阶段;如果先前已经进行了确定性变异(passed_det=1)或者种子得分满足某个条件[对该种子进行确定性变异性价比不高],则也需要跳过确定性变异跳过确定性变异后,先执行用户自定义的变异阶段,之后进入havoc阶段。
havoc阶段结束后,可能会进入splice阶段,该阶段由
afl->ready_for_splicing_count(>1)决定,该值在add_to_queue()函数中被更新,当种子大小>4时,afl->ready_for_splicing_count++